
Outline:
? What is user churn?
? Reducing user loss is a top priority for businesses.
? Ten strategies for reducing user churn.
How to Improve the User Churn Rate ? Here are 10 Strategies.,首發(fā)于Cobub。
]]>Outline:
? What is user churn?
? Reducing user loss is a top priority for businesses.
? Ten strategies for reducing user churn.
Many companies do not have specific plans to activate silent users and recall lost users. Some companies try to replace lost users with new users, while others spend a lot of time analyzing problems and trying to prevent users from losing them.
Before we discuss the methodology for reducing user churn, we need to understand how user churn is defined.
What is user churn?
User churnrefers to the number of users who leave the product within a specified period of time. According to different products and different businesses, the time period is different. The user loss indicator shows the ability of the product to retain users from the side. Companies will pay a heavy price for the loss of their users.
Data talks
When it comes to the impact of user churn, research has done the statistics, and the cost of getting new users is five times the cost of retaining existing ones. The harvard business school report also points out that a 5 percent increase in retention rates can lead to a 25 to 95 percent increase in profit. There are also data suggesting that retained users are major contributors to corporate revenue.

According to gartner, a consultancy, 20% of retained users will contribute 80% of the company’s future revenues. At the same time, the chances of successful sales to the remaining users are 60-70%, and the chances of successful sales to new users are only 5-20%.

The above data shows that reducing user loss and improving retention of users is the most important and beneficial to enterprises (especially e-commerce enterprises).
What are the adverse effects of user loss on the enterprise?
? Reduce enterprise income, affect enterprise performance.
? Lower corporate profitability.
? Improve enterprise marketing and user recall costs.
There are 10 strategies for reducing user churn.
1. Analyze the reasons for user loss.
Why do users lose? The answer also needs to be found in the user, the most direct way is to talk with the user. Phone calls are the quickest way to talk to users. By telephone, we can know that our products do not solve the users’ pain points, what problems we have caused to users and so on. In addition to phone calls, we can also find out the reasons for the loss of users by sending emails to users, inviting users to comment on the website, or interacting with users on social media.
2. Maintain user engagement.
Maintaining user engagement can help prevent user loss to some extent. In order to maintain user engagement, we need to continue to prove the value of the product to the user. In addition to letting users know the main functions of the product and updating the content of the iteration, we can also show users new transaction information, special offers or recent preferential activities, etc.
Previous face-to-face interactions have been the main way for users to participate, but new research shows that websites and social media are becoming the main ways for users to participate.

Getting new users involved in the product is also a good way to reduce user churn. For example, we can ask new users about the first impression of the product, which helps us understand the initial impact of the product.
3.Give users adequate guidance.
Reducing user churn can be achieved by providing users with high-quality guidance/support information. These guidelines include but are not limited to free training, online BBS, video guidelines or product demonstrations. Good product functionality with enough guidance not only gives users the tools to solve problems, but also gives users a guide to the tools they use. The greatest potential of our products and services is to let users feel that we are paying enough attention to them and that it is not so easy for users to leave their products.
4. Timely detection of users on the edge of loss.
Data from the past loss of user behavior through the analysis, we can come to the conclusion that some loss of user joint behavior, such as they lost before that time is not as active as ever, loss and puts forward some problems to us before but didn’t get our feedback and so on. By identifying these common features, we can predict users who are on the edge of loss and take appropriate measures to retain them.
5. Identify high-value users.
Identifying high-value users and prioritizing the needs of these users is important because our revenue is primarily contributed by these high-value users. There are two ways to identify high-value users: one is to analyze the engagement of users in each stage of the product life cycle, and the other is to group users according to user behavior. We can have a high degree of engagement at each stage of the product life cycle, and the user group that often implements the purchase behavior is considered a high-value user group.
When analyzing user engagement and the behavior of different user groups, we can not only identify high-value users, but also identify users who are on the edge of loss. In other words, we can also predict the loss of users as we determine the high value users.
6. Incentive
There are many ways to motivate users, such as preferential activities, points exchange, etc. In incentives to retain on the verge of losing users or recall has been lost, we must ensure that these measures cost consumed less than these users to our contribution to profits. We can’t afford to waste a lot of human resources to save those who won’t contribute a dime.
7. Target users.
In As A Product Manager, Do You Really Understand the Data Analysis?,We have a product vision – the product must be targeted. After all, the target user is barking up the wrong tree, even if we make the most of it and we can’t let the user stay. If we use words like “free” and “cheap” to attract new users, our new users may not be our target users at all. Those who collect freebies are the most likely to lose. Our target users should be users who value the long-term value of our products, not those who are greedy and cheap.
8. To provide better service to users.
Poor service can lead to loss of users. There are two main reasons for the loss of users: one is incompetent and rude staff, and the other is that the service is too slow to be tolerated. More than 70 percent of the lost users are lost to bad services.

The image above shows the importance of user service. Any service that makes users dissatisfied can lead to loss of users.
9. Value user complaints
The product problem exposed by user complaints is only the tip of the iceberg. According to the survey, 96% of users will not be satisfied even if they are dissatisfied with the product, and 91% of them will leave without a word. Only 4% of users will complain about the product!

Therefore, we must take users’ complaints and complaints seriously and give timely feedback. Research shows that users who receive feedback and solutions are more likely to become loyal users, who can spread our products or services to form a good reputation.
10. Show our competitive advantage.
We need to make it clear to the user that we are different from our competitors; Where we stand out; If users don’t use our products, they will miss something. Knowing these problems, we can see what our competitive advantage is. After knowing the competitive advantage, we can hype it up!
We’ve talked about 10 strategies to reduce user loss, and we want to help the people who run the APP.
How to Improve the User Churn Rate ? Here are 10 Strategies.,首發(fā)于Cobub。
]]>
對于大多數(shù)廣告主來說,廣告投放的目的無非就是吸引更多的用戶,提升廣告ROI,最終實現(xiàn)營銷轉(zhuǎn)化。
Data Analysis: How to Optimize Advertising ROI?,首發(fā)于Cobub。
]]>For most advertisers, the purpose of advertising is to attract more users, improve the ROI, and finally realize the marketing transformation. But they also pay more attention to the information, such as:
Is the advertisement on time?
Is the media/advertising company committed to achieving this?
Is the data produced by the media/advertising company real?
Did the media cheat?
Whether the investment in advertising is proportional to the output… And so on.
Why should advertisers care? Here is an example of the cost of the laptop in ZOL:

From above, it is not difficult to see, for advertisers advertising expenses are a lot of spending, each advertising need to invest a lot of money, who all want to each cost spent. To understand the above questions, you should know the meaning of the various data indicators in the advertisement, so as not to be deceived by the false information.
The mystery behind the advertising figures.
There are a lot of indicators of advertising effectiveness. Each monitoring index reflects different data effects, such as the rate of jump and arrival rate, and whether the response advertising effect has reached the media’s promise. The amount of exposure, the amount of clicks reflected CPC and CPM are not enough, and the regional distribution of advertising audiences is not correct.

And the dimensions of the dimensions that are released are different. For example, the purpose of promoting brand is to focus on the number of clicks, the number of clicks, the number of clicks, and the number of users to reach the number of users; Focus on the arrival quantity, the number of users, the number of two jumps and the total number of views. To guide the user to participate in the activity to focus on the conversion and conversion of users; To promote sales for the purpose of focusing on conversion details.
Compared with the media data, advertisers pay more attention to the advertising effect.
The data indicators reflect the results of the release, but in the actual operation, in the face of various advertisements, which location, which media is the best? How to measure advertising effectiveness? Which ads are effective? What media combinations are really effective… .. ? This series of problems is also the focus of advertisers.
So how to solve these problems in advertising and achieve accurate delivery? This needs to optimize advertisement release, the problem that appears in advertisement release is solved in time.
I. Understand the basic methods of evaluating advertising effectiveness.
Advertising effectiveness evaluation generally around hits (exposure), reach the quantity, second jump, into four indicators to assess the amount of, each indicator to measure the advertising data of different stages, through these data to help us analysis of the problems existing in advertising. So we use a funnel to show you:

One of the things we want to focus on is that the amount of click here is more important than the amount of exposure. Because measuring the effect of advertising is to measure “the target audience of contact advertising”, it is not accurate to use the exposure code. This is because:
1. The number of exposure codes is not equal to the amount of advertising exposure (the actual number of advertisements displayed)
2. The amount of advertising exposure is not equal to the number of people who see the advertisement (the Internet advertising form varies widely, the same exposure amount of advertisements, the number of people who really notice/see may be huge)
3. The person who sees the advertisement is not the target audience of the brand.
There are three levels of difference, so it is not accurate to use exposure to measure the “target audience”. Click the quantity to reflect the real effect, the exposure amount for reference.
II.Understanding transformation.
Advertising is inseparable from the media resources. Through the website, we need to know this information:
Which areas bring more registered users, which search engines bring more orders, which advertising channel has the highest conversion rate, which landing page brings the highest conversion rate and so on.

By mastering these transformation information, we can help us analyze and transform the situation, such as:
? The transformation of the external source website can directly reflect the quality of the website’s netizens, while combining the external source traffic to reflect the conversion rate effect of each source.
? The transformation details can be used to analyze the effect of each specific transformation, as an evaluation basis for the CPS effect.
III.Understand traffic.
The most important thing is to have traffic. Where does the traffic come from? Which channels bring more users, and which areas bring more… .. Through the analysis of traffic source, help us to optimize the adjustment of advertising channels and advertising programs. Such as:
1. According to the external inbound traffic inflow and the second jump rate ranking, brush selected high-quality sources, and eliminate the bad sources.
2. According to the traffic curve of the website, learn the habits of Internet users and choose the best advertising content.
3. According to the changes in the traffic period of the website, find the laws and abnormal points of the flow, and then find out the deep causes, find the problems in time, and adjust the delivery.

IV. Distinguish the quality of traffic.
In the process of advertising, often meet the false traffic, the phenomenon such as malicious click, so the quality of the evaluation flow has four elements: malicious click, false and landing page content access flow, good flow user activity. At the same time, false and low quality flow has the following characteristics:
? The flow data of 24 hours is very uniform, without obvious characteristics.
? The flow chart in the sky is high and low, and the fluctuation is very intense.
? Click, arrival, and jump rates are very similar across the country.
? The landing page is rarely clicked and almost nothing gets noticed.
? The visitor’s browsing depth is close to 1.
In a word, good advertising optimize ultimate purpose is to improve advertising ROI, actually in the final analysis in a word, spent it is to make every cent advertising work, so how to make every advertising works, is make every AD measurable, let each AD last effect can be precise Numbers to show, so that accuracy is higher, just also can maximize advertising value.
Data Analysis: How to Optimize Advertising ROI?,首發(fā)于Cobub。
]]>The product details page is the most easily accessible and resonant page of the e-commerce APP. The quality of the product details page design has a direct relationship with the user purchase conversion rate.Therefore, the good design of the product details page can stimulate users' desire to purchase, dispel misgivings and enhance the trust of users!
Let's take a look at the electricity funnel model: pull new (new users), active (commodities list page, page for details) - buy transformation (order, payment, trade complete) - spread (evaluation, sharing).
How to Make People Buy Buy Buy on December 12th?,首發(fā)于Cobub。
]]>The product details page is the most easily accessible and resonant page of the e-commerce APP. The quality of the product details page design has a direct relationship with the user purchase conversion rate.Therefore, the good design of the product details page can stimulate users’ desire to purchase, dispel misgivings and enhance the trust of users!
Let’s take a look at the electricity funnel model: pull new (new users), active (commodities list page, page for details) – buy transformation (order, payment, trade complete) – spread (evaluation, sharing).

In the process of operating electric business APP, we tend to be the focus on access to new users and to generate income, many people think that as long as there are constantly new users into and someone buy, our APP operation was very successful.In fact, as long as we take effective measures against the product details page, it will be easy to pull new, buy, and disseminate these indicators.Good product details page can bring us more revenue, better customer experience and better APP performance.
Want to talk about is here, in front of the design product details page to fully market user research, user through the analysis of the historical data of consumption ability and interest preference, accurately understand the needs of users, there is not much more.Below, we will discuss the design of the product details page, and give the following five strategies and Suggestions:
1. Reduce the number of buttons and simplify the operation process
Purchased in design process, we can only provide users with a CTA button (call to action, used to motivate the user action button), it can avoid to cause the user to choose difficulties can also encourage users to buy. Since there is only one CTA button, we have to figure out what kind of action the user wants to take. The “add to cart” button gives the user time to think, although it is the user’s point of view, but this can cause a certain disturbance to the user’s purchase behavior. We can think about our own online shopping scene: a lot of times when we add our products to our shopping cart, we will think, wait a while, maybe there will be a discount later? If only “buy immediately” button, this button will induce the user to purchase the item when browsing the product. Acceleration of the purchase process is conducive to the purchase of conversion rate.

2.Magnify the CTA button to stimulate the user to purchase
Magnify the CTA button to make the CTA button appear more visible, allowing users to interact with the product more and stimulate more purchases. The design of the CTA button is too small to be coordinated in the full details page. The “instant buy” button in the atmosphere is more likely to encourage users to click.

3.Guides the user through the text on the CTA button
CTA button intuitive persuasive words such as “buy now” can also, but “accept for their own” very good use of the weakness of human nature of greed, desire, possession of mental state, when to see their favorite things, we all hope that this thing is belong to own.

4.Place star rating in a prominent position on the screen
There’s a lot of information that can be displayed on the screen, and there’s no shortage of star ratings and ratings. Because good grades and reviews can help users quickly learn about the popularity of the product, it can also help to establish an authority in the user’s mind. Second, placing the evaluation in a prominent position on the screen allows users to make a good impression on the product.

5.Add the social sharing button to the product details page to promote communication
Adding social media buttons not only encourages users to share, but also facilitates user sharing. We are mainly used to share items on the current page. But in fact, the true use of marketing should not be limited to the product itself. For example, the record of successful purchase, or the interaction between the buyer and the seller, can be Shared content, which will be more communication than the commodity itself.

The above 5 points suggest that we can combine the A/B test to verify and ensure that the user behavior data we collect is accurate and effective. In the end, I wish you all the e-business friends 12-12 barley!
How to Make People Buy Buy Buy on December 12th?,首發(fā)于Cobub。
]]>
A pretty average number is created with the data of virtual scene, will give our decision making misleading, so we need to acquire an effective method to analyze the real user behavior and user value, this method is a Cohort Analysis (Cohort Analysis).In fact, the data does not lie, but the analysis of the data is not accurate analysis and leads to the incorrect interpretation of the data.
At the same time, there are relatively few studies related to the group analysis in China. Perhaps not all operations know about the group analysis in the same period, but it is a necessary analysis method for every product operation.In the famous "lean data analysis", the soul of test data analysis also mentions the relevant content of group analysis in the same period.
In the same period, group analysis was first used in the field of medical research to observe how the behavior of different subjects varied with time.By monitoring different groups of subjects, medical researchers can observe the effects of different prescriptions and treatments on the subjects and determine the Shared behavioral patterns. ]]>
A pretty average number is created with the data of virtual scene, will give our decision making misleading, so we need to acquire an effective method to analyze the real user behavior and user value, this method is a Cohort Analysis (Cohort Analysis).In fact, the data does not lie, but the analysis of the data is not accurate analysis and leads to the incorrect interpretation of the data.
At the same time, there are relatively few studies related to the group analysis in China. Perhaps not all operations know about the group analysis in the same period, but it is a necessary analysis method for every product operation.In the famous “lean data analysis”, the soul of test data analysis also mentions the relevant content of group analysis in the same period.
In the same period, group analysis was first used in the field of medical research to observe how the behavior of different subjects varied with time.By monitoring different groups of subjects, medical researchers can observe the effects of different prescriptions and treatments on the subjects and determine the Shared behavioral patterns.
So in terms of operations, what is the same cohort?
In the same period, the group belongs to a subgroup of users, which refers to the group of users who have the characteristics of common behavior within the specified time.“Common behavior” refers to the similar behavior in a certain time period, which in addition to sort them out according to different time of new users, may be classified according to different behaviors, such as “in June 2017 for the first time to buy”, “on the second week of October, 2017 products began to reduce the use of frequency”, etc.
Note that the cluster analysis focuses on the differences between groups during the same phase of the customer’s life cycle.
Why is Cohort Analysis important?
In the process of product development, we usually measure product revenue and product user volume as the ultimate measure of success or failure of this product.There is no denying that these indicators are important, but they could not be used to measure the product’s success recently, and most likely will hide some issues which need our attention, such as user engagement has been falling, added in gradually slow, etc.On the analysis of user behavior in the process, we need more detailed measures, so that is better for us to accurately predict product development and by version iteration in a timely manner to product optimization and improvement.
Cohort Analysis is the key to improving the retention of APP users
The success of a product, it says, is not how many downloads it is, but how to keep losing users and how to recall them.
We can’t through downloads to determine the specific situation of the development of the APP, because beautiful download data will mislead us thought APP development is very healthy, but in fact, many users download is lost in a few days.Group analysis is the key to improve user retention.
case
For the first time, users of the APP were analyzed in the same time group and observed their retention for the next seven days.
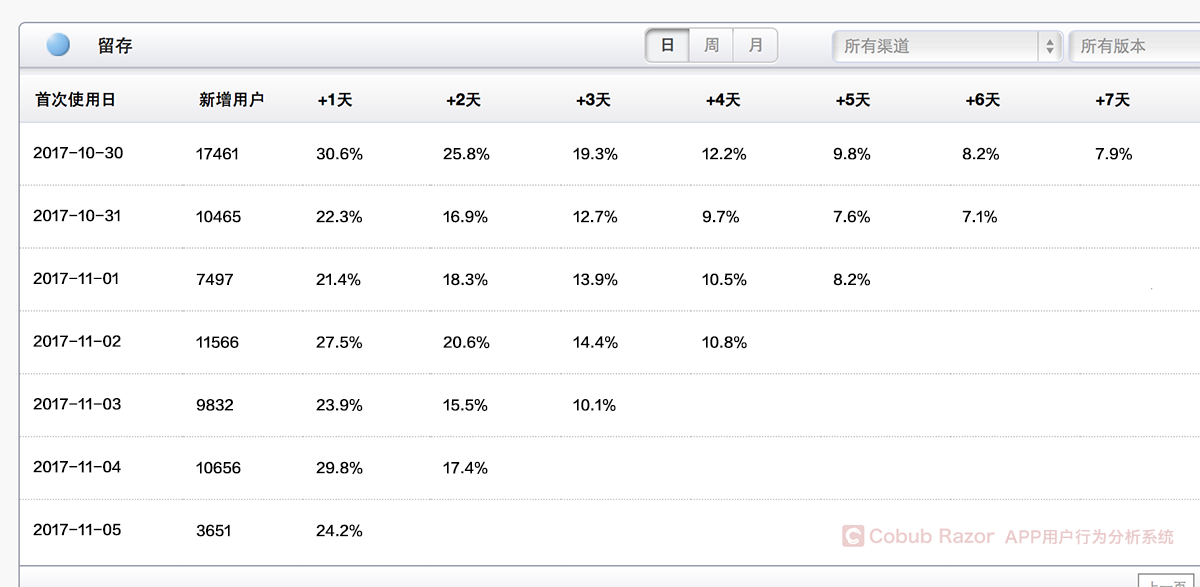
17461 new users start the APP, for the first time in October 30, with 30.6% of people in these users on the first day to start again, the fourth day 12.2%, 7.9% on the seventh day, and this shows that at the time of the seventh day approximately once every 12 users only one active users.It also means we lose 92% of our users
We need to know which groups have better retention and analyze why.Have we launched a new marketing campaign on that day?Or offers promotions or discounts?Or new features that add video to the product?We can apply these successful strategies to other users to improve user activity and retention.We can also compare the retention of different time periods:
? The preservation of the new lads:
By comparing the different time groups, we can see four days, seven days and so on.These data can give us the key information about user login experience, product quality, user experience, and market demand for products.
? Long-term retention:
By looking at the number of days a group of users are returning to use the APP again, we can see the long-term retention of each cohort, rather than the remaining days of the new APP.
We can know where the user is out, and you can know what’s the feature of active users, what they are doing and so on the one hand, will help us in new quickly find target users, on the other hand we can also affect the new users, let them follow the same route, eventually become loyal users.
Cohort Analysis can help us monitor real user behavior, measure user value and develop targeted marketing programs in real time
For example, our operations team launched a 60-day welcome campaign in September to promote user growth through a series of discounts and offers.Through advertising and social media, we have thousands of users growing every day.Five months later, our user growth was very large, and the leader was very satisfied with the result of our activity.
On the face of it, we have achieved the goal of user growth.However, when we study cohort data, starting from the lifetime value of customers, we will find that new users welcome activities in activity 2 months after purchase rate continue to reduce, by contrast, activity before the new users such as users in August, in the activities of this five months purchase rate has been stable.
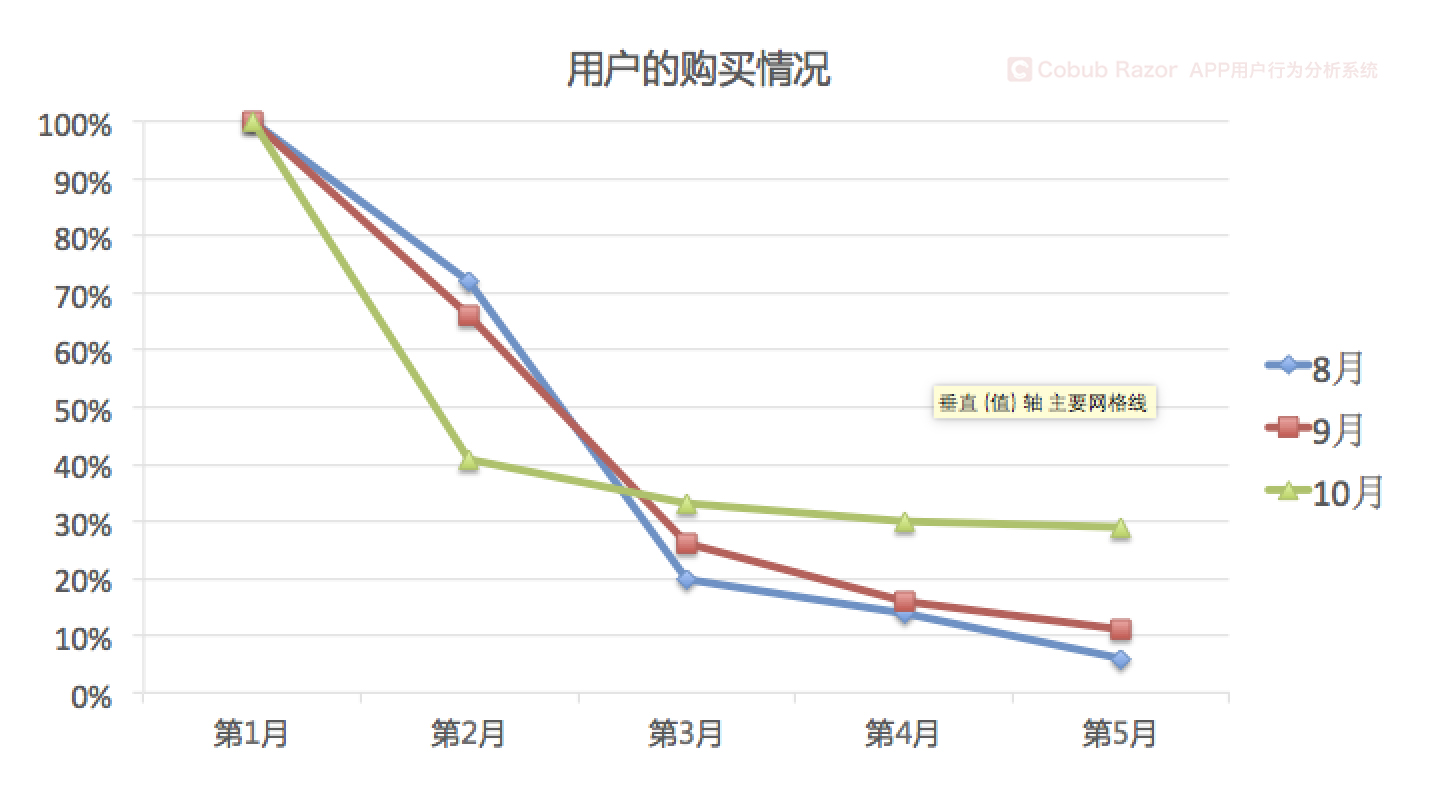
If we only measure our monthly gross income as a measure, we expect revenue growth to come only from the new influx of users.However, user group data following the launch of the activity shows that once the discount activity is over, revenue will decline.The decline in revenue proves that we have not expanded our loyal user base.
As shown above, through the cohort analysis we can real-time monitoring the real user behavior trend, otherwise, we will get wrong judgment because only analyze the overall data and make the wrong decision.By analyzing the behavioral differences of each cohort, we can develop targeted marketing programs.In this case, the operator needs to develop a new strategy to improve user engagement after two months of activity.
How to implement Cohort Analysis?
Start by defining business questions
Defining a business query is a prerequisite for the study of effective results.Business questions define business goals and research attempts to solve them.
Does the customer purchase conversion rate increase after we optimize the product?Is the user turnover rate reduced after the product improvement?We need to iterate and refine these questions to ensure that it is aligned with business objectives.
Define metrics based on business queries
If the purchase conversion rate and user retention rate are the key indicators to answer business questions, we want to understand the user turnover rate and the final purchase conversion rate from registration to completion of purchase.
Definition cohort
In the previous cases, the group was based on the user who purchased the account within a week of creating an account.In other cases, we can define a group in a different way, for example, a content APP that we might post within 24 hours of creating an account.
Analyze group data over the same period
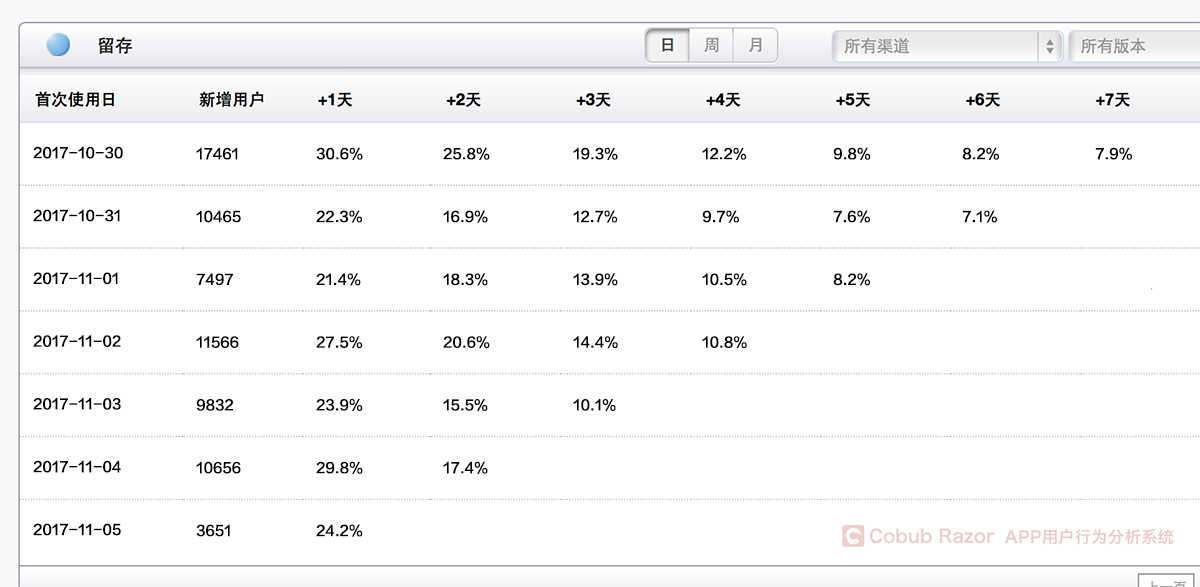
We also in a cohort of typical form, for example, rows horizontally for natural number, longitudinal for every new clients, forms the internal is to calculate retention rate every day, usually the retention rate of lateral will stay some days later in a relatively stable state, we can see from the picture, keep stable in 5 days.This means that the users are stable.Otherwise, if the retention rate keeps going down, it’s going to go to zero someday.
Let’s look at the longitudinal retention data, and if a product is in healthy development, this data should be getting better and better.Obviously this product is not, the PM should constantly improve the product according to the historical data, improve the user experience, thus improve the retention rate!
Conclusion
Cohort Analysis in the same period will help us to analyze user behavior more deeply and reveal the problems covered by the overall measure.In the current situation where the marketing mode and the activity effect are changing, learning to use the same period group analysis can help us to predict the future income and product development trends.
]]>Why Can’t You Help Clicking It?,首發(fā)于Cobub。
]]>How exactly is this habit developed?
Why do we habitually open an App?
Why do some products stop us from losing our addiction to other products?
Is there any secret to making users more comfortable with your product?

According to cognitive psychologists, the so-called habit is a kind of “unconscious behavior that is produced in the context of the situation”, which we make almost without thinking about it.These days, the products and services we take for granted are changing our every move, and that’s what the product designers were trying to do.That is to say, our behavior has been designed unconsciously.
How do these companies manage to influence users’ habits and control their thinking with just a few encoded characters on their electronic screens?What are the factors that make people want these products?
Making users develop habits and dependencies is an essential element of many products.Nowadays, more and more enterprises have realized soberly, with only has a huge customer base is not enough to constitute a competitive advantage, the user the product a high degree of dependency is the key to decide its economic value.
So, are you ready to learn more about cultivating positive user habits?And then, looking down, you’re going to get a whole new understanding of the addiction model.
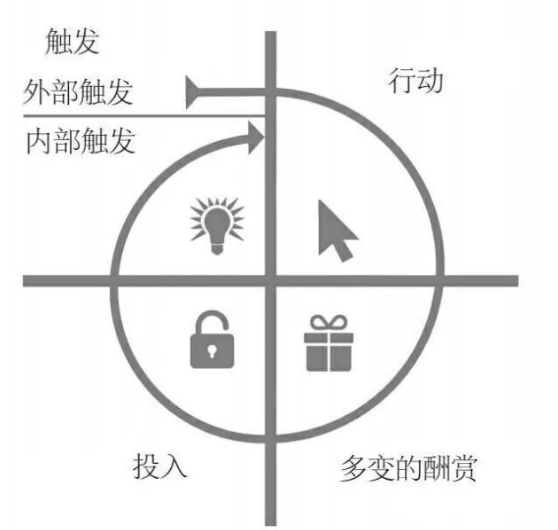
The four stages of the addiction model – trigger, action, variable reward, commitment
Trigger: remind people to take the next step
Triggering is the first stage of the addictive model, which triggers the user to trigger action.There are two types of triggers: external triggers and internal triggers.Let you produce habitual rely on those products are often the external trigger the first to play a role, it is through the information penetration in all aspects of your life to guide you to take the next step, such as email, website links, or the application icon on the phone.
Use an external trigger is just the first step, trigger is the inner core, it through the user memory storage in various association to remind them to take the next step, negative emotions can often act as internal trigger.Develop habits to develop product designers need to consider the user’s psychology, to understand those likely to be internal trigger emotions, and to know how to use external trigger to help users to take action.

Action: the direct response of people when they expect a reward
The trigger is action.If they fail to act, the trigger fails to take effect.Dr Fogg, of Stanford university, argues that to get people to act, three elements are essential: motivation (M), ability (A), triggering (T).I’ll write it in terms of the formula, which is B= MAT.
Triggers remind you to take action, and motivation determines whether you are willing to take action.The motivation for users to use products is based on people’s pursuit of happiness and the avoidance of pain.The pursuit of hope, the avoidance of fear.And because people want to be identified, they hate being rejected.So, as long as your product can give users happiness, hope and identity, it can be the motivation for user action.
With an inner itch (trigger), there is a willingness to tickle, and users can easily “scratch”.The ease of use of the product directly affects the user’s usage of the product.To successfully simplify a product, we have to clear the way for users to use the process.Fogg, summarizes the influence degree of task difficulty of six elements: time required to complete this activity, economic investment, physical, mental, and others on acceptance of this activity, and the degree of match between the activity and routine activities or contradiction.When designing the product, figure out what is preventing the user from completing the activity.Is the user no time, or no money?Is it a busy day and don’t want to think again, or is the product too difficult to operate?To win hearts, you have to make your product easy and easy to navigate.
Therefore, to increase the incidence of preconceived behaviors, the trigger should be obvious, the behavior should be easy to implement, and the motivation should be reasonable.
Changeful reward: satisfy the user’s demand, arouse the desire to use
In the third stage, your product will be able to satisfy users’ needs and arouse their desire to use more.What drives the user to take action is not the reward itself, but the desperate need to be rewarded.The difference between an addiction model and a normal feedback loop is that it can inspire a strong desire for something.The feedback loops around us are not uncommon, but the feedback loops that can be seen in the results do not help to create the inner desire.
The variable reward of “installation” of products is a magic weapon used by the company to attract users.Fundamentally, variable rewards must meet their needs while appealing to users.There is often more than one reward for products or services that can kill users in seconds.Products that don’t have the advantage of being in a variety of variability have to be constantly updated to keep up with The Times.
Social raise reward
The interpersonal rewards obtained through interaction with others.For example, when a friend gets married, he sends out a circle of friends and receives a wave of blessings, which is a social reward.We like our “circle”, enjoy the “likes” of others, and expect “comments” from others.Social rewards can make users crave and expect more.
Prey to reward
Get resources or information.Such as microblogging, microblogging began to attract people, because people as long as the repetition of a “rolling” behavior, can search to the interesting information that oneself like, this is hunting reward mechanism, content variety provides users with unpredictable attractive experience.
Reward yourself
Experience the sense of manipulation, the sense of accomplishment, and the sense of closure.The “upgrade” in the game affects the evaluation of mastery and ability of the self, and the game rules of upgrading and acquiring privileges can satisfy the players’ desire to prove their own strength.Even mundane emails, the number of unread emails in mailboxes are like tasks for many people, a task that needs to be done.
The variable reward is a powerful tool to attract users.Insight into why people habitually rely on products helps designers to design their products well.
Input: through the user’s input to the product, cultivate “repeat customers”
But it’s not enough to get the product to the user’s mind.
A one-night red product often has a good trigger, an easy operation, and a rich social reward.But without the ability to “invest” in a long time, hot style will lose users’ attention over time.
It turns out that the more we invest in things, the more likely we are to think of it as valuable, and the more likely we are to be consistent with our past actions.Finally, we change our preferences to avoid cognitive dissonance.This is the last stage of the addiction model, and it is a stage where users have to invest.The input phase is related to the customer’s expectation of long-term reward, which has nothing to do with timely satisfaction.
When a user provides their personal data and social capital for a product, spending their time, energy, and money is what has happened.In other words, investing doesn’t mean letting users spend money; it means the behavior of the user can improve the quality of subsequent service.Add attention, add to the collection, expand the virtual assets, understand the new product functions, all these are the input that users pay to improve the product experience.These inputs have an effect on the first three stages of the addiction model, and triggers are more likely to form, and action is more likely to occur, and reward is more attractive.
You must say, everything has a routine, then know the routine, how to reverse the pattern?
As a product manager, you can use the addiction model to compare your products:
What do users really need?What pain can your product alleviate?(internal trigger)
What attract users to your product?(external trigger)
What is the simplest operation a user can take when expecting a reward?How do I simplify this operation?(action)
Are users satisfied with the reward, or do they want more reward?(variable reward)
What are the “drips” that users make to your product?Do these inputs help to load the next trigger to improve product quality during use?(input)
If you are a user and learn about these “design patterns”, you can take targeted “anti-design, anti-pattern”.Check your daily actions: what situations do you automatically run on an App?When is the easiest time to swipe your phone?What are the driving forces behind it, to kill time, or to relieve stress?Make a note of it.Find your own behavioral patterns and intrinsic drivers to consciously control your behavior.
文/ 小歐 微信公眾號:中歐國際工商學(xué)院
本文改編自《上癮:讓用戶養(yǎng)成使用習(xí)慣的四大產(chǎn)品邏輯》一書
Why Can’t You Help Clicking It?,首發(fā)于Cobub。
]]>1 Ambari profile
Apache Ambari project by developing software is the purpose of the hadoop cluster configuration, monitoring and management, in order to make the management more simple hadoop.Ambari also provides a RESTful interface implementation based on itself of intuitive, easy-to-use web management interface.
Ambari allows system administrators to the following:
1. Provide installation management hadoop cluster;
2. Monitor a hadoop cluster;
3. The extension ambari custom service management functions.
Ambari Installation and Custom Service Initial Implementation,首發(fā)于Cobub。
]]>1 Ambari profile
Apache Ambari project by developing software is the purpose of the hadoop cluster configuration, monitoring and management, in order to make the management more simple hadoop.Ambari also provides a RESTful interface implementation based on itself of intuitive, easy-to-use web management interface.
Ambari allows system administrators to the following:
1. Provide installation management hadoop cluster;
2. Monitor a hadoop cluster;
3. The extension ambari custom service management functions.
2 Basic conditions needed for cluster
2.1 The demand of the operating system
? Red Hat Enterprise Linux (RHEL) version 5. X or 6. X (64);
? CentOS v5. X, 6. X (64) or 7. X.
? Oracle Linux version 5. X or 6. X (64);
Selection of this document is the CentOS version 6.5 (64);
2.2 System based on software requirements
On each host to install the following software:
(1) yum and RPM (RHEL/CentOS/Oracle Linux);
(2)zypper(SLES);
(3)scp,curl,wget;
2.3
The demand of the JDK
Oracle JDK 1.7.0 _79 64 – bit (default)
Its 7 64 – bit (SLES does not support)
3 Before installing the software prerequisites
3.1 Ambari and the conditions needed for monitoring software
Ambari before installation, in order to guarantee ambari services and the normal operation of the various monitoring service, according to different operating systems, the need to determine some already installed software version, software version must conform to the requirements listed below.I.e., if the existing system has the following software, version must be exactly the same as that of the versions listed below, if not the installation program will be installed on its own.
Software configuration precedent chart 3-1 table


3.2 Ambari and HDP version compatibility
Due to a software version upgrade, compatibility between versions due to the version may cause some problems.
Table 3-2 version compatibility

4 Install examples
In this paper, the choice of system and the software version, shown in the table below:
Table 4-1 system and software version
![]()
4.1 Installation Ambari before the operation of the system
4.4.1 configuration host name
Ambari cluster configuration information is through the fully qualified hostname to determine the cluster machine information, so you have to make sure it is the host name.
4.1.2 Configure cluster information
Hosts file on each machine to do mapping configuration, command is as follows:
# vi /etc/hosts
Then add the following content:
Table 4-2 IP mapping information table

4.1.3 Configure SSH password free exchange
First of all, the primary node and other nodes are executing the following command, to ensure that each machine can produce the public key.
![]()
Then enter all the way. Then each node’s public key to form a new authorized_keys file, then distributed to each node. Thus, completed each node from the login operation.
4.1.4 Configure NTP time synchronization
In the first place on the primary node to do the following:
(1) install the NTP time server:
#yum install ntp
(2) modify the NTPD configuration file
(3) open the time synchronization server
#sevrice ntpd start
(4) in each from the other nodes to do the same operation, thus the NTP synchronization is complete
4.1.5 Closed selinux
Permanently closed SELinux
# vi /etc/selinux/config
Change the SELINUX = enforcing to SELINUX = disabled
Restart to take effect, restart command as follows:
# reboot
4.1.6 Close iptables firewall
Permanent closure (need to restart)
# chkconfig iptables off
(need to restart the firewall temporarily shut down the firewall services)
service iptables stop
Check the firewall status
# chkconfig –list|grep iptables
Note: other services under Linux can use the above command to perform opening and closing operation
Restart to take effect, restart command as follows:
# reboot
4.2 Create yum local source
First check whether the master node HTTPD installation server, the command is:
rpm -qa |grep httd
If not, the installation, the command is:
#yum install httpd
Start the HTTPD
#service httpd start
chkconfig httpd on
All the files inside the folder and subfolders granted the same rights, the command is:
chmod –R ugo+rX /var/www/html
Open the network
vim /etc/sysconfig/network-script/ifcfg-eth0
Modified to onboot = yes
After successful installation, Apache working directory in/var/WWW/HTML by default.
Configuration:
Check whether the port is occupied, Apache HTTP service using port 80
[root@master ~]$ netstat -nltp | grep 80
If there is a footprint, installed after the need to modify the Apache HTTP service port number:
[root@ master ~]$ vi /etc/httpd/conf/httpd.conf
Modify the listener port, Listen to other port 80.
To download the installation files in the/etc/WWW/HTML, then start
[root@ master ~]$ service httpd start
Can check my http://master in the browser to see some of the Apache server page information, said started successfully.
5 The preparation for installation of completely offline Ambari
The difference between offline and online installation yum use different warehouse location, namely the remote installation package in the warehouse a share in local resources such as copies, and then create these resources in the yum warehouse package folder local repository package, can be installed in accordance with the online way to go.But needed to be resolved offline installation Ambari RPM package dependency problem, the first to make sure that postgresql8.4.3 has been installed, or a local postgresql8.4.3 warehouse.
5.1 Prerequisites
Ambari offline installation, you need to use yum, if it is a new installation of operating system, may lack a lot of necessary conditions, the following form according to the order of the once upon a time in the future, in turn, has achieved certain conditions, if can skip those conditions.
Because of complexity of the software operating system itself, such as the installation of tooltips have other required software or existing software upgrades, according to clew to solve it.
5.2 Establish a local repository
HTTP service installed on a machine within the cluster, and then will provide the tar packages or put the RPM package on the machine/var/WWW/HTML directory can be the default directory (Apache) under decompression, the best in this directory to create a new directory, all ambari tar packages and HDP and HDPUTIL is placed in it and extract the tar package, if the machine does not have to manually install PostgreSQL, will provide the software packages together into the local repository.
5.3 Set yum is not check GPG key
Tested off-line yum install Hadoop cluster, it is GPG key check to install software and lead to errors, can through the closed system at this time of yum GPG check to avoid mistakes
# vi /etc/yum.conf
Set gpgcheck attribute value is 0
gpgcheck=0
5.4 Installation ambari services
# yum –install ambari-server
5.5 Ambari Settings
# ambari-server setup
Will appear after the operation whether enter ambari – server daemon, choose the JDK, configuration information such as database, can undertake choosing according to the requirements of the system itself.
When there is a “Ambari Server setup completed successfully”, explain Ambari – Server configuration is successful.To be sure, the database of installation option is a PostgreSQL database, in which the user and the database is the default in advance good;If choose the MySQL database, the need before installing the Ambari – server build user, giving permission, built a database, and so on.
Then start ambari – server, according to the need to install the hadoop ecosystem services.
The custom service service
1 Ambari custom extension service
From the first part, the ambari for secondary development function, the main job is to research the components such as integrated into the ambari, monitoring and management. This paper is to integrate redis.
First, because the service is belonging to the stack, so it decided to customize a service belongs to which stack., again because you have installed HDP2.5.0 stack, so this paper will set the service to place under the stack of HDP2.5.0. New service called: redis – service, including structure diagram as shown in the figure below:

Including configurate the XML file to configure this module call main installation is complete package service main q control in the life cycle of python file, metainfo. The XML file is defined mainly asked some attribute of the service, the metrics. The json and widgets. Json controls the service interface diagram shows.
The metainfo. XML instance as follows:
2.0
REDIS-SERVICE
Reids
My Service
1.0
MASTER
Master
MASTER
redis
1
PYTHON
5000
SALVE
Slave
SLAVE
1+
PYTHON
5000
any
Second, we need to create a Service life cycle control script master. Py and slave py.Here need to ensure that the script path and in the previous step metainfo. In XML configuration path is the same.The two Python script is used to control the Master and Slave module of life cycle.The meaning of the script function as well as its name: install is install call interface;Start, stop, respectively is start-stop call;The Status is regularly check the state of the component invocation.The master. Py and slave. Py template for:
Master.py
class Master(Script):
def install(self, env):
print "Install Redis Master"
def configure(self, env):
print "Configure Redis Master"
def start(self, env):
print "Start Redis Master"
def stop(self, env):
print "Stop Redis Master"
def status(self, env):
print "Status..."
if __name__ == "__main__":
Master().execute()
Slave.py
class Slave(Script):
def install(self, env):
print "Install Redis Slave"
def configure(self, env):
print "Configure Redis Slave"
def start(self, env):
print "Start Redis Slave"
def stop(self, env):
print "Stop Redis Slave"
def status(self, env):
print "Status..."
if __name__ == "__main__":
Slave().execute()
Again, the redis RPM installation file into the HDP installation package/var/WWW/HTML/ambari/HDP/centos6 / directory.
Again, restart ambari – server, because ambari server only when the restart will read Service and Stack configuration.The command line: ambari – server restart.
Finally, the login Ambari GUI, click on the lower left corner of the Action, select Add Service.The diagram below:

At this point you can see in the list of installation service Redis service. Then check whether the service installation is successful.
2 Ambari implement custom extensions service interface display
Service in the first quarter of the second chapter mentioned metircs. Custom json and widget. The json, the widget is a Ambari figure controls appear in Web Metrics, it will according to the value of the Metrics, to make a simple aggregation operation, finally presented in figure control.Widget is Ambari further enhance the ease of use, and can be configured.Widget is displayed AMS Metrics collected properties.
Then last here, including the metrics. Json template for:
{
"REDIS-MASTER": {
"Component": [
{
"type": "ganglia",
"metrics": {
"default": {
"metrics/total_connections_received": {
"metric": "total_connections_received",
"pointInTime": true,
"temporal": true
},
"metrics/total_commands_processed": {
"metric": "total_commands_processed",
"pointInTime": true,
"temporal": true
},
"metrics/used_cpu_sys": {
"metric": "used_cpu_sys",
"pointInTime": true,
"temporal": true
},
"metrics/used_cpu_sys_children": {
"metric": "used_cpu_sys_children",
"pointInTime": true,
"temporal": true
}
}
}
}
]
}
}
widget.json:
{
"layouts": [
{
"layout_name": "default_redis_dashboard",
"display_name": "Standard REDIS Dashboard",
"section_name": "REDIS_SUMMARY",
"widgetLayoutInfo": [
{
"widget_name": "Redis info",
"description": "Redis info",
"widget_type": "GRAPH",
"is_visible": true,
"metrics": [
{
"name": "total_connections_received",
"metric_path": "metrics/total_connections_received",
"service_name": "REDIS",
"component_name": "REDIS-MASTER"
}
],
"values": [
{
"name": "total_connections_received",
"value": "${total_connections_received}"
}
],
"properties": {
"graph_type": "LINE",
"time_range": "1"
}
}
}
At this point, restart ambari – service, command is as follows:
ambari-server restart
3 Data acquisition and sending
Using shell script to run redis information data acquisition and one-time send to the metrics of the collector, the script is as follows:
#!/bin/sh
url=http://$1:6188/ws/v1/timeline/metrics
while [ 1 ]
do
total_connections_received=$(redis-cli info |grep total_connections_received:| awk -F ':' '{print $2}')
total_commands_processed=$(redis-cli info |grep total_commands_processed:| awk -F ':' '{print $2}')
millon_time=$(( $(date +%s%N) / 1000000 ))
json="{
\"metrics\": [
{
\"metricname\": \"total_connections_received\",
\"appid\": \"redis\",
\"hostname\": \"localhost\",
\"timestamp\": ${millon_time},
\"starttime\": ${millon_time},
\"metrics\": {
\"${millon_time}\": ${total_connections_received}
}
},
{
\"metricname\": \"total_commands_processed\",
\"appid\": \"redis\",
\"hostname\": \"localhost\",
\"timestamp\": ${millon_time},
\"starttime\": ${millon_time},
\"metrics\": {
\"${millon_time}\": ${total_commands_processed}
}
}
]
}"
echo $json | tee -a /root/my_metric.log
curl -i -X POST -H "Content-Type: application/json" -d "${json}" ${url}
sleep 3
done
Run the following commands (note here is that parameters 1 is the Metrics of the Collector machine, is not a Ambari Server machine) :
./metric_sender.sh ambari_collector_host total_connections_received redis
Process if no accident, wait for 2-4 minutes to interface with data display. Through the above operation, can be implemented to include ambari not in monitoring management software to monitor.
Ambari Installation and Custom Service Initial Implementation,首發(fā)于Cobub。
]]>How do we get the push messages to the desired effect?APP operators must pay close attention to the behavior of users, have a clear preference for users' interests, and push the content of interest to different groups of users at the right time.The perfect push messages are valuable to the user, which can help the product to improve the user experience and increase the user's liking.
Who: Object
What: Content
When: Time
Where: Situation
Why: Reason ]]>
How do we get the push messages to the desired effect?APP operators must pay close attention to the behavior of users, have a clear preference for users’ interests, and push the content of interest to different groups of users at the right time.The perfect push messages are valuable to the user, which can help the product to improve the user experience and increase the user’s liking.
Who: Object
What: Content
When: Time
Where: Situation
Why: Reason
Figure out these 5 Ws, then we can push messages satisfying users’ need.
1. Why: Why do we push this message?
“Why” always comes first, with every push message having a clear goal — to make the user login for the first time or for the user to upgrade?Not only do we need to know the target of the push message, but we need to know what behavioral data we want from the user.These behavioral data are used to measure the impact of push messages on users.For example, after the user logs on to a social APP for the first time, it will receive the following information, which is the push we made to get users to improve their personal data.
2. What:What do we push?
The content of the push messages have the following three characteristics:
(1)Targeted:
Sometimes small details can play a big role.In the example above, we added the user’s name before the message was sent to the user. “Hi, XXX, welcome…”Instead of sweeping to the point: “welcome…Plus the name makes the user feel more approachable.
(2)Ensure relevance and timeliness:
Push messages must be timely and highly relevant to users.Netease news, for example, is pushed to the user’s nanjing tomorrow weather news, reflects the correlation between geographical position, this message is to push on Friday afternoon, Saturday’s travel plans to give the reference for the user to remind, the right time.

(3)Accurate and rapid direct user pain points:
The user’s time is precious, and the message we push must get the user to the maximum value.Do not push spam messages to users, or do not match the user’s needs.For example, messages for users who don’t have a car.
3. Who: Who are we going to push the news?
The push message object cannot be cut and cut. We need to divide and manage the user through user behavior data.When it comes to user behavior, here are a few more common user behavior analysis platforms, such as friends union, baidu statistics, etc.But these SaaS platforms also have problems, and the raw data is difficult to export, and the data of their own products cannot be owned by us.It is also easy to recommend Cobub Razor, data private and backstage construction.
Different push messages receive different recipients.
We provide personalized news feeds based on the user’s behavior habits, preferences and so on.For example some music APP users to listen to music for different style, favorite star and collection of song single push related update alert, such precision push has greatly raised the proportion of the user to open the message.
4. When do we push the news?
(1)Time of day:
Can select the user free time, such as before going to work in the morning, at noon to eat, after dinner, specific choice which push period, can according to user’s use time was used to determine, in short not to interrupt the user when user busy or rest.
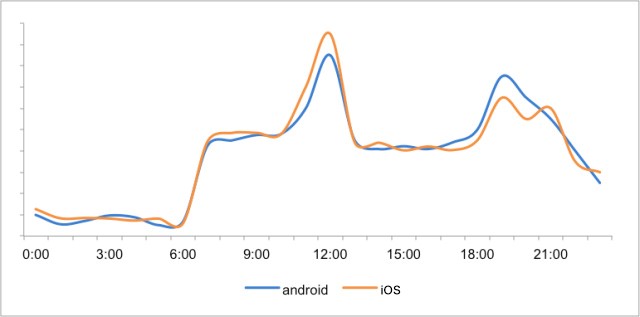
A time period for users of a financial app
(2)Push frequency
Too high push frequency can result in two kinds of results — the user clicks on the push and immediately turns off, or the user simply ignores the message and doesn’t even look at it.The number of push frequency should be determined according to the type of application, generally speaking, the social App can be pushed daily, the information class can be 3-4 times a week, the tool class 1-2 times a week.The number of times should not be too much, otherwise the user will not open up, and probably close the message push, even uninstall the application.
(3)Local time:
Push messages need to be determined according to the user’s local time, this needs us according to the user’s location to determine if your users from all over the world, Beijing time at four o ‘clock in the afternoon when Washington is at four o ‘clock in the morning.If we unified Beijing time to push the news, users in Washington would be disturbed.
5. Where: What situation are we pushing in?
Push scenes can also affect the effect of push messages.We need to consider where the user is when the push message arrives, what he is doing, or what device the user is using when he receives a push message.
We, as users, receive a lot of notifications every day. For example, the taxi app will push express coupons for me on Friday after work.The group purchase app will push the group purchase information of the restaurant near me at mealtimes.If the user is in a disturbed state when they receive a push message, then the user will not be able to look at the push message and take action that we expect.

The messages in the application are pushed based on user behavior, so the effect is better.Regardless of the user, lie sofa eating, no matter the user on the PC, mobile end, as long as we clearly understand the user behavior, according to their behavior push related news, the user is there is a strong possibility we expect action.
Conclusion
The perfect push message must be pre-defined by 5W.Through 5W, we make clear the target, content, object, push time and scene of the push message, so that the user can see the value of the push message to the user.Pushing is the best user touchpoint, and it’s more important to make a thoughtful product that fits the user’s habit than it does daily.
]]>In recent years, data analysis has developed rapidly and we have also made a micro data analysis tool.The product has been successfully operated for three years, fulfilling the daily life of millions of enterprises.The product structure is very simple, with the simplest language in the world PHP, the most common database mysql, the server can choose apache or choose nginx, all your own preferences.
1. Microservice architecture diagram:
Three Years Running, a Million Micro-service Data Analysis Framework,首發(fā)于Cobub。
]]>In recent years, data analysis has developed rapidly and we have also made a micro data analysis tool.The product has been successfully operated for three years, fulfilling the daily life of millions of enterprises.The product structure is very simple, with the simplest language in the world PHP, the most common database mysql, the server can choose apache or choose nginx, all your own preferences.
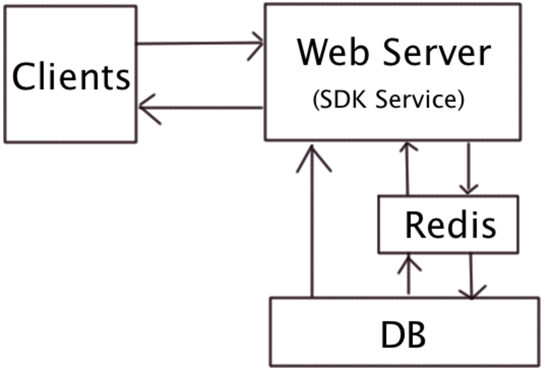
1. Microservice architecture diagram:
Whole flow chart:
(1) The SDK uploads data to the server, and if redis is installed, the data will be advanced to redis and then periodically extract the data to the DB server. Redis can greatly improve parallel data processing capabilities.
(2) The database collects raw data, and the stored procedure calculates the data according to different dimensions according to different dimensions, and the data summary table.
(3) Front desk report presentation, real-time report, hour report and day report data display. It’s better to write and separate.
2. Functional framework

The functional architecture includes functions, roles, and permissions. The function is enterprise service, the user USES each function, is the enterprise every service. The role is the user action category, the function and the role’s correspondence and permissions. Understand the status of the system architecture and start with the functional architecture.
3. Application framework
The application architecture includes existing architecture diagrams, web application status, and interface architecture. Among them, the interface is the key to the application layer, which is the interaction between programs.
The main interface includes clientdata usinglog event and errorlog, etc.
The SDK sends data to the background periodically through the interface.
The application architecture lists the end-to-end invocation relationships.
4. Data design
Two databases, about one hundred tables. The design of the database relies on business data, classifies business data, and results in an E_R diagram of data design. The data design is completed and the final database design comes out. As long as early design of the database, it can be easy to scale, easy to split. Statistical classes are mainly divided into statistical dimensions, which are user, device, error information, etc.
(1) Data handling capacity
The number of live millions, the number of launches is about two million, and the number of events and page views is at least 300 to five million, with an average of 500,000 data per hour. During operation, the customer data volume is concentrated in the morning and evening peak. According to the special situation of customers, some tasks are arranged in the leisure time, such as daily tasks, weekly tasks, monthly tasks, etc. Good hardware configuration is a good helper for data processing, and larger memory faster drives can definitely make data flow fast.
(2) Data cleaning and read-write separation
A large amount of raw data is entered into the database, which is then processed into garbage data. When all report data is counted and writes to the various dimension tables, the data needs to be removed periodically.
The front desk report shows that data is best separated from the storage analysis database.
5. Physical Schema
A microservice’s physical architecture requires very little machinery, and a machine can run. Analysis statistics is mainly about data processing ability, the database server needs two, and the web side needs one. Many years of operation result and database processing capacity are the biggest bottleneck of statistical analysis.
6. The direction of continual optimization
(1) Data read and write separation, data cleaning.
(2) Concurrent volume.
7. Customers
Customer’s most important data:
The most important thing for each customer is user table, user’s new status, user activity, user retention. Different customers require different user requirements to determine whether the user is using the machine, and the user has a mapping relationship with the device number and user ID (user number).
Event data is also important, relational conversion rate.
Page access is just as important as events.
Error data can detect bugs in the application.
Different customers, different usage scenarios have different requirements for indicators.
Three Years Running, a Million Micro-service Data Analysis Framework,首發(fā)于Cobub。
]]>
Every product manager knows that data analysis is important, but can you give a clear answer to both of these questions?
1. What is data analysis?
2. Why is data analysis so important?
It doesn’t matter if you don’t know the answer, because this article is about to answer it from the following aspects:
1. What is data analysis?
2. Relevant concepts of data analysis
3. How to conduct data analysis?
4. How to measure and collect data?
5. How to do data analysis report?
6. The relationship between data analysis and products
As a Product Manager, Do You Really Know about Data Analysis?,首發(fā)于Cobub。
]]>Every product manager knows that data analysis is important, but can you give a clear answer to both of these questions?
1. What is data analysis?
2. Why is data analysis so important?
It doesn’t matter if you don’t know the answer, because this article is about to answer it from the following aspects:
1. What is data analysis?
2. Relevant concepts of data analysis
3. How to conduct data analysis?
4. How to measure and collect data?
5. How to do data analysis report?
6. The relationship between data analysis and products
What is data analysis?
In short, data analysis represents product status, user behavior, and what users click on and so on. Although the data represents the state of the product, it does not indicate the cause of the state of the product. Data analysis cannot rely solely on a single measurement data, which should be based on a series of converging data.
For example, if you want to analyze the state of an object, we can’t use temperature only, you have to combine other data like position, velocity, composition, environment temperature etc. to implement data analysis. Suppose the velocity is 0, the object is 1 meter above the ground, and the surrounding temperature is the same as the object, and you can conclude that the object is static.
Similarly, when you analyze product status and user behavior, the more metrics you gather, the better for you.
Relevant concepts of data analysis
To get the most out of data analysis, you need to be very knowledgeable about the concepts of data analysis. These concepts include:
? Data points
? Segmentation
? Funnel
? Cohorts
Data points
Data points, the single point of data. A data point measures a particular project, including measurement data and time.
Accurate data points are the premise of our chart of product development trends.
Segmentation
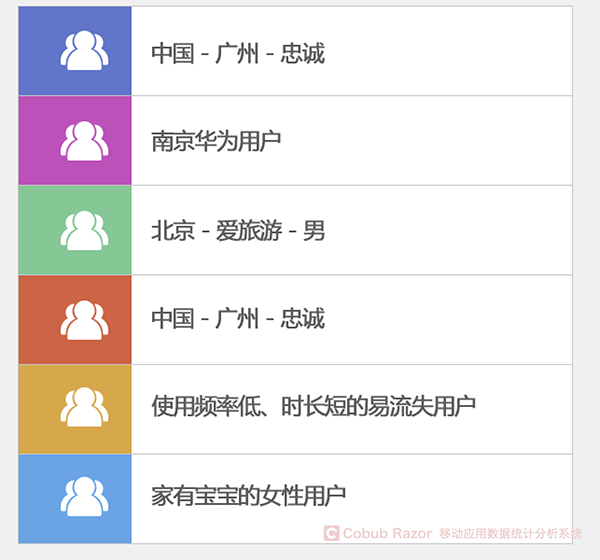
Segmentation is based on user’s common characteristics and product usage pattern.
Segmentation is based on but not limited to:
? Technology (browser, operating system, equipment, etc.)
? Behavior (first time visit, return visit, etc.)
? Demographic (language, country, etc.)
If you do not do segmentation by the above characteristics, you have to do it by the ones that can be measured. For example, user gender is a feature that can be measured. As long as we add gender to the user profile, we can collect relevant data.
You can understand the user’s potential behavior patterns through segmentation. Average data masks these patterns of potential behavior. For example, you add first visits vs return visits as the segmentation feature, although the average page views is 2, you find that for first visits, the average page views is 1.2, the average page views of return visits was 3.4. Without segmentation, the difference in page views of first-time visitors and return visitors will be covered by the average page views.
With segmentation, you can focus on the main target user groups. For example, if your target users are located in eastern China, you only need to analyze the user behavior in different provinces in eastern China instead of analyzing users from all around China to optimize the product to adapt to the targeted users’ needs.
Funnel
The funnel model is mainly used for daily data operation and data analysis, such as flow monitoring and product target transformation.
To achieve the goal, the user performs a series of actions. For example, on the e-commerce platform, users will perform the following operations to achieve the purpose of purchase:
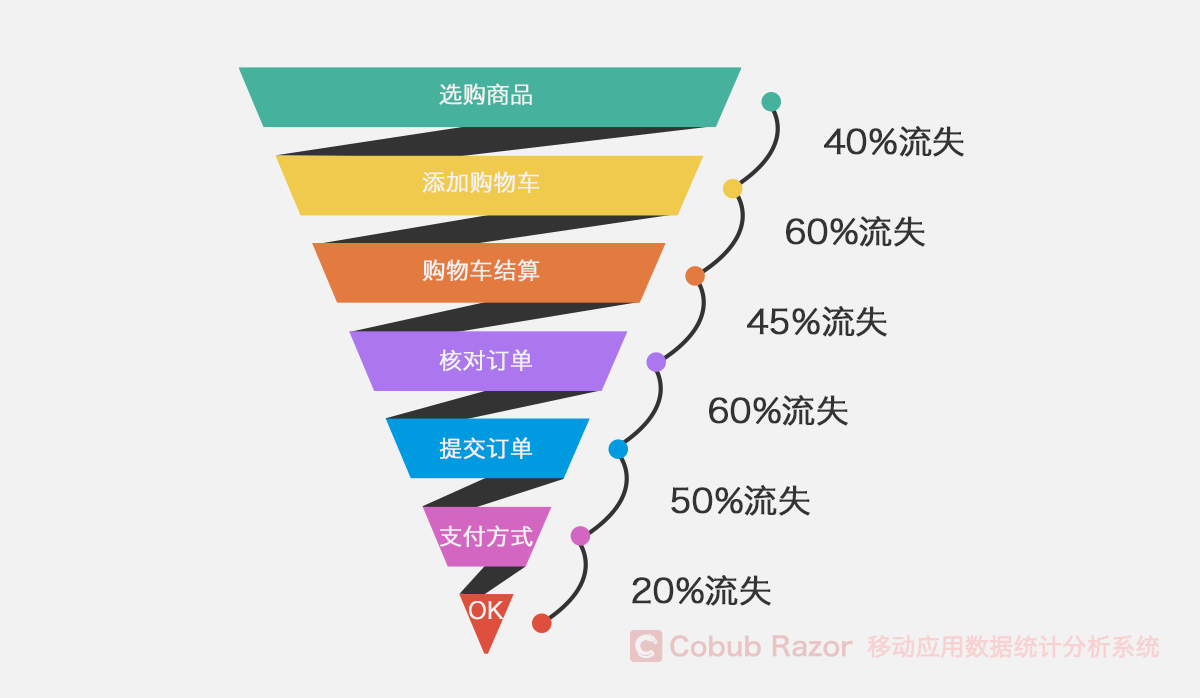
Through the funnel model, we can find out where the user is losing and find out the reasons for the loss through the investigation and analysis.
Cohorts
Cohorts is similar to segmentation, the difference is that cohorts is to compare and analyze user behavior over time.
Cohorts is helpful for measuring the long-time value of users.
Cohorts can compare differently, for example, we can compare a week ago registered users and registered users, a month ago can also compare the registered user of a particular date. If we don’t have a group for a week ago and a month ago, the new user will disturb our analysis of the user behavior during these two periods. When compared to a user of a particular time period, we can measure the impact of a marketing campaign or a product’s function update on user behavior.
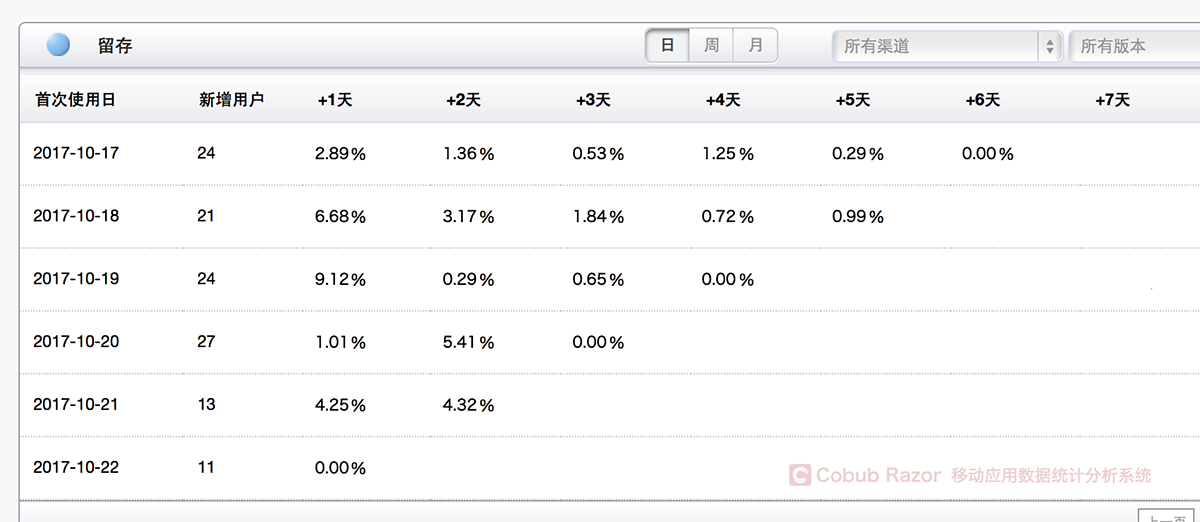
The figure above is a retention diagram based on user registration time. On October 8, the number of users remained significantly higher compared with other users. When we look at this data, we can explore what is causing the change in user retention.
How to conduct data analysis?
Product managers are exposed to massive amounts of data, so how do we perform data analysis? We need to make the following plan:
1. Define product vision
2. Define KPI that meets product vision
3. Definitions allow us to achieve the metrics of KPI
4. (Through user behavior logging) define the funnel that affects measurement
In order to make a better plan, we need to understand the relevant concepts in the plan.
Product vision
Product vision refers to product usage and target users. In short, “what problems does the product solve for users?” Without product vision, all of our next action is a waste of time.
KPI
KPI measures product performance. La new, retained, active, transmutation and so forth are the categories of KPIs. We can also use KPIs to set product development goals, such as increasing user registration by 20% or increasing the purchase conversion rate by 30%. KPIs should be suitable for the stage of the product. If we are just starting out, the main KPI is the user registration, not the user activity.
Metrics
Metrics are the means to achieve KPI. Metrics generally have conversion rate, purchase rate, and so on. By computing two or more data points, we can get metrics. At the same time, the change trend of measurement indicators is also the basis of product improvement.
Funnel
The important funnel will change the metric in some way. After establishing the product use process/user behavior log, we develop the relevant funnel model based on the metrics and user behavior. The funnel model produced by the registration rate and the conversion rate is not possible.
Getting data points
Obtaining measurable data points to achieve KPIs, calculate measurement indicators data, make funnels significant.
The plan is not static, we need to update the plan according to the product vision and KPI.
How to measure and collect data?
There are two methods: establishing an internal analysis system or relying on a third-party analysis system. The internal analysis system can be customized based on metrics. The downside is that we need to build and maintain resources individually.
External analysis systems, such as Google Analytics, Mixpanel, KISSmetrics, etc., are good options. Third-party analysis systems are easy to implement without wasting the resources needed to build and maintain them. Cobub Razor is a professional APP data statistical analysis tool in China, which supports privatization deployment. The data is flexible and safe. It is a good choice.
How to do data analysis report?
Usually we do data analysis reports by making comparison charts and trend charts.
A comparison chart shows a change in a metric between two point points, such as a metric that changed between last week and this week. It allows us to see whether there are large fluctuations in the metric between two time points.
A trend chart shows changes in a metric over a period of time, such as changes in a metric over the past month. It shows the direction of the measure, indicating whether the product is performing — better, worse, or not?
The report identifies the problem and then tries to answer “why does XX happen?” “Why does YY change?” These problems, we can optimize and improve the product.
The relationship between data analysis and products
We improve the product according to the data analysis results. If there is no data analysis, we can easily change the product blindly and make head decisions. If there is no data analysis, we cannot know the effect of product change. In the process of product development, we need to constantly conduct data analysis to ensure that our products are developing according to our expectations.
To ensure that products are in a leading position, product managers must know what data analysis is and the importance of data analysis. Hope this article can be helpful to the general product manager.
As a Product Manager, Do You Really Know about Data Analysis?,首發(fā)于Cobub。
]]>