
文章概要:
? 什么是用戶流失?
? 減少用戶流失是企業的首要任務
? 減少用戶流失的十種策略 ]]>
文章概要:
? 什么是用戶流失?
? 減少用戶流失是企業的首要任務
? 減少用戶流失的十種策略
很多企業并沒有制定激活沉默用戶和召回流失用戶的具體方案。也有些企業試圖通過獲取的新用戶來頂替流失用戶的空位,另一些則花大量時間分析問題并想盡辦法阻止用戶流失。
在討論減少用戶流失的方法論之前,我們首先得明白用戶流失是如何定義的。
什么是用戶流失?
用戶流失是指在特定時間段內離開產品的用戶數量。根據不同的產品及不同業務,時間段的確定也各不相同。用戶流失指標從側面表明產品留住用戶的能力。企業會為用戶的大量流失而付出慘重代價。
讓數據說話
談到用戶流失的影響,有研究機構做過統計,獲取新用戶的成本是留住已有用戶成本的五倍。哈佛商學院的報告也指出,用戶留存率上升5%可以帶來25-95%的利潤提升。同樣有數據表明留存用戶是企業收入的主要貢獻者。

根據高德納咨詢公司(美國咨詢公司)的數據,20%的留存用戶將貢獻公司未來收入的80%。同時,將產品成功銷售給留存用戶的幾率是60-70%,而成功銷售給新用戶的幾率只有5-20%。

以上各種數據表明,減少用戶流失,提升用戶留存對企業(尤其是電商企業)來說最重要并且最有益。
用戶流失會對企業造成哪些不良影響
? 降低企業收入,影響企業業績
? 降低企業收益率
? 提高企業營銷和用戶召回成本
減少用戶流失有10個策略
1. 分析用戶明確用戶流失的原因
用戶為什么會流失?答案還需要從用戶身上找,最直接的辦法是與用戶交談。電話回訪是與用戶對話最快的方式。通過電話回訪用戶,可以知道我們的產品沒有解決用戶的哪些痛點,我們給用戶造成了哪些困擾等等。除了電話回訪的方式,我們還可以通過給用戶發郵件、邀請用戶到官網評論留言或者在社交媒體與用戶互動的方式查找用戶流失的原因。
2. 保持用戶參與度
保持用戶參與度可以在某種程度上防止用戶流失。為了保持用戶參與度,我們需要持續向用戶證明產品對其產生的價值。除了讓用戶知道產品的主要功能和更新迭代的內容,我們還可以向用戶展示新的成交消息、特價商品或者近期的優惠活動等等。
以前面對面交流是用戶參與的主要方式,但新的研究數據表明,網站和社交媒體也逐漸成為用戶參與的主要途徑。

讓新用戶參與到產品也是減少用戶流失的好方法。例如,我們可以詢問新用戶對產品的第一印象,這有助于我們理解產品所產生的初始影響。
3. 給予用戶充分的指導
減少用戶流失可以通過給用戶提供高質量的指導/支持資料的方式實現。這些指導包括但不限于免費培訓、在線論壇、視頻指導或者產品演示等等。好的產品功能加上足夠的指導不僅讓用戶有解決問題的工具,也讓用戶擁有使用工具的指南。我們發揮產品和服務的最大潛力,讓用戶感受到我們對其足夠重視,用戶想要離開產品就沒那么容易。
4. 及時發現處在流失邊緣的用戶
通過對以往流失用戶的行為數據進行分析,我們可以總結出一些流失用戶共有的行為,譬如他們流失之前的那段時間不像以往那樣活躍,流失之前向我們提出了一些問題但沒有得到我們的反饋等等。通過發現這些共同特征,我們就能預測處于流失邊緣的用戶并采取相應的措施來挽留他們。
5. 確定高價值用戶
確定高價值的用戶并且優先滿足這些用戶的需求非常重要,因為我們的收入主要由這些高價值的用戶貢獻。 辨別高價值用戶的方式有兩種:一是分析用戶在產品生命周期內每個階段的參與度,二是根據用戶行為對用戶進行分組。我們可以將在產品生命周期每個階段參與度都很高,并且經常實施購買行為的用戶群組視為高價值用戶群。
在分析用戶參與度和不同用戶群組的行為時,我們不僅可以確定高價值用戶,還可以確定處在流失邊緣的用戶。也就是說,確定高價值用戶的同時,我們也能預測即將流失的用戶。
6. 激勵用戶
激勵用戶的措施有很多,例如優惠活動、積分兌換等。在采取激勵措施挽留處于流失邊緣的用戶或者召回已流失用戶前,我們一定要確保這些措施所消耗的成本低于這些用戶給我們貢獻的利潤。我們不能浪費大量的人力財力去挽回那些不會再為我們貢獻一分一毫的用戶。
7. 找準目標用戶
在《作為產品經理,你真的了解數據分析嗎?》這篇文章里,我們有提到產品愿景——產品一定要找準目標用戶。畢竟,目標用戶找錯了,哪怕我們使盡渾身解數也不可能讓用戶留下來。如果我們通過“免費”和“便宜”這樣的字眼來吸引新用戶,我們獲取的新用戶可能根本不是我們的目標用戶。這些收集免費贈品的用戶是最有可能流失的群體。我們的目標用戶應該是重視我們產品長期價值的用戶,而非那些貪小便宜的用戶。
8. 向用戶提供更好的服務
糟糕的服務會導致用戶流失。用戶流失有兩大主要原因:一是不稱職又粗魯的員工,二是服務慢到讓人無法容忍。因糟糕服務而流失的用戶占流失用戶的百分之七十多。

上圖足以證明用戶服務的重要性。任何讓用戶不滿的服務都可能導致用戶流失。
9. 重視用戶投訴
用戶投訴所暴露的產品問題只是冰山一角。調查顯示,96%的用戶即使對產品感到不滿也不會吭聲,而且其中91%的用戶會一聲不響地永久離開。只有4%的用戶會對產品提出不滿或意見!

由此可見,我們必須認真對待用戶的抱怨和投訴并且及時給予反饋。研究表明,這些投訴得到反饋和解決的用戶更有可能成為忠誠用戶,而這些忠誠用戶可以傳播我們的產品或服務從而形成好口碑。
10. 展示我們的競爭優勢
我們需要讓用戶明白我們與競爭對手有什么區別;我們突出的地方在哪里;如果用戶不使用我們的產品,他們會錯過什么。搞清楚這些問題之后,就能知道我們的競爭優勢有哪些。清楚了競爭優勢之后就可以大肆宣傳啦!
以上我們講述了減少用戶流失的10個策略,希望對APP運營的小伙伴們有幫助。

對于大多數廣告主來說,廣告投放的目的無非就是吸引更多的用戶,提升廣告ROI,最終實現營銷轉化。 ]]>
對于大多數廣告主來說,廣告投放的目的無非就是吸引更多的用戶,提升廣告ROI,最終實現營銷轉化。但同時他們也更加關注這些信息,比如:
廣告是否按時投放?
媒體/廣告公司承諾的量是否達到?
媒體/廣告公司出示的數據是真實的嗎?
媒體有沒有作弊?
廣告的投入與產出是否成正比……等等。
廣告主為什么會在意這些?我們以下圖為例,筆記本在ZOL投放的費用明細:

從上圖不難看出,對于廣告主來說廣告費用是一筆不小的支出,每一筆廣告投放都需要投入大量的資金,誰都希望每一筆費用都花在刀刃上。想要了解上述各種題就要知道廣告投放中的各項數據指標所代表的意義,這樣才不會被虛假信息所蒙蔽。
廣告投放數字背后的玄機
廣告效果指標分很多,每一種監測指標反映不同的數據效果,比如二跳率、到達率等反應廣告效果有沒有達到媒體的承諾;曝光量、點擊量反映CPC、CPM夠不夠,廣告受眾地域分布反應投放的區域受眾人群是不是正確等信息。

同時投放的維度不同監測的指標也不同。比如以推廣品牌為目的重點關注點擊量、點擊用戶數、點擊IP數,以及到達量、到達用戶數 ;以引入流量為目的重點關注到達量、到達用戶數、二跳量以及總瀏覽量;以引導用戶參與活動為目的重點關注轉化量、轉化用戶數;以促進銷售為目的重點關注轉化明細。
與媒體數據指標相比,廣告主更加關注廣告效果。
數據指標反映了投放的結果,但在實際操作過程中,面對形式繁多的廣告,哪個位置,哪個媒介是最好的?如何衡量廣告效果?其中哪些廣告是有效的?哪些媒介組合是真正有效的呢…..?這一系列問題也是廣告主所關注的。
那么在廣告投放中,如何解決這些問題,實現精準投放呢?這就需要對廣告投放進行優化,對于廣告投放中出現的問題及時解決。
一、了解評估廣告效果的基本方法
廣告效果評估一般圍繞點擊量(曝光量)、到達量、二跳量、轉化量四個指標來評估,每一個指標衡量不同階段的廣告投放數據,通過這些數據幫助我們分析廣告投放中出現的問題。據此我們用一個漏斗圖為大家展示一下:

其中我們要重點提一下,這里的“點擊量”比“曝光量”更重要。 因為衡量廣告效果一般是要測算“接觸廣告的目標受眾”, 用曝光代碼來統計并不準確。這是因為:
1、曝光代碼觸發次數 ≠ 廣告曝光量(廣告實際展示次數)
2、廣告曝光量 ≠ 看到廣告的人數(互聯網廣告形式千差萬別,同樣曝光量的廣告,真正注意到/看到的人數差別可能巨大)
3、看到廣告的人 ≠ 品牌的目標受眾
這中間有3級差異,所以用曝光來測算“接觸到廣告的 目標受眾”很不準確。 點擊量才反應真實效果,曝光量作參考。
二、了解轉化
廣告投放離不開網站這個媒介資源,通過網站,我們要了解這些信息:
哪些地區帶來的注冊用戶多,哪些搜索引擎帶來的訂單多,哪個廣告渠道的轉化率最高,哪個著陸頁面帶來的轉化率最高等等。

通過掌握這些轉化信息,幫助我們分析轉化的情況,比如:
? 外部來源網站的轉化量,可以直接體現該網站的網民質量,同時結合外部來源流量,體現各來源的轉化率效果。
? 轉化明細可以將每一個具體轉化的效果剖析出來,作為廣告CPS效果的評估依據。
三、了解流量
廣告要實現轉化,最重要的一點就是要有流量,流量從哪里來?哪些途徑帶來的用戶多,哪些地區帶來的多…..通過流量來源分析,幫助我們優化調整廣告投放渠道和廣告方案。比如:
1、根據外部來運網站流入量和二跳率排名,刷選優質來源,剔除劣質來源。
2、根據網站流量曲線規律,了解網民登錄網站的習慣,選擇最佳的廣告內容發布時間。
3、根據網站流量時段變化,發現流量的規律和異常點,進而查找深層原因,及時發現問題,調整投放。

四、區別辨別流量質量
在廣告投放過程中,常常遇見虛假流量,惡意點擊等現象,因此評估流量的質量有四大要素:惡意點擊、虛假流量、著陸頁面內容訪問、流量用戶的活躍度。同時虛假、低質流量具有以下特征:
? 24小時的流量數據非常均勻,沒有明顯特征
? 以天為單位的流量圖時高時低,波動非常劇烈
? 全國各個地區的點擊、到達、二跳比率非常接近
? 著陸頁面點擊很少,幾乎沒有任何內容被關注
? 廣告訪客的瀏覽深度接近1層
總之,做好廣告投放優化最終目的就是提高廣告ROI,其實歸根到底一句話,就是讓花出去的每一分廣告費都起作用,那么如何讓每一個廣告都起作用呢,其實就是讓每一個廣告都變得可衡量,讓每個廣告的最后效果都能用精確的數字來展現,這樣精準度才會更高,廣告價值也才會最大化。
本文來源于數據分析網,作者99click商助科技
]]>商品詳情頁是電商APP中最容易與用戶產生交集和共鳴的頁面,商品詳情頁設計的質量,與用戶購買轉化率有著直接的關系!因此,商品詳情頁面設計的好可以激發用戶的購買欲,打消顧慮,增強用戶的信任感!
下面我們來看一下這個電商漏斗模型:拉新(新用戶)——活躍(商品列表頁、商品詳情頁)——購買轉化(下單、付款、交易完成)——傳播(評價、分享)。 ]]>
商品詳情頁是電商APP中最容易與用戶產生交集和共鳴的頁面,商品詳情頁設計的質量,與用戶購買轉化率有著直接的關系!因此,商品詳情頁面設計的好可以激發用戶的購買欲,打消顧慮,增強用戶的信任感!
下面我們來看一下這個電商漏斗模型:拉新(新用戶)——活躍(商品列表頁、商品詳情頁)——購買轉化(下單、付款、交易完成)——傳播(評價、分享)。

在運營電商APP的過程中,我們往往都是將重心放在獲取新用戶和獲取收入上,很多人以為只要有源源不斷地新用戶涌入并且有人購買,我們的APP運營就很成功。實際上,只要我們針對商品詳情頁采取有效措施,拉新、購買、傳播這些指標數據的提升都會變的很容易。好的商品詳情頁可以給我們帶來更多的收入、更好的客戶體驗以及更好的APP表現。
在這要講一下的是,在設計商品詳情頁前要進行充分的市場用戶調研,通過歷史數據分析用戶的消費能力及興趣偏好,準確了解用戶的需求,這里就不多贅述。下面我們來具體聊一下商品詳情頁的設計,給出以下5點策略及建議:
1. 減少按鈕數,簡化操作流程
在設計購買流程時,我們可以只提供給用戶一個CTA按鈕(call to action,用于激發用戶行動的按鈕),這樣既可以避免給用戶造成選擇困難還可以鼓勵用戶購買。由于只有一個CTA按鈕,我們必須搞清楚最想讓用戶采取什么樣的行動。“加入購物車”按鈕雖然是站在用戶的角度考慮,給予了用戶思考的時間,但是這會對用戶的購買行為產生一定的干擾。我們可以想想平時自己網購的場景:很多時候我們將商品加入購物車之后就會想著,先等一段時間,說不定以后會有折扣呢?如果只有“立即購買”按鈕,這個按鈕在用戶瀏覽商品的過程中就會誘導用戶購買。加速了購買的進程,有利于購買轉化率的提升。

2.放大CTA按鈕,刺激用戶購買
放大CTA按鈕,讓CTA按鈕看起來更顯著,能讓用戶更愿意與產品互動,刺激更多購買。CTA按鈕的設計太小,在整個詳情頁屏幕里會顯得不協調。大氣的“立即購買”按鈕更能刺激用戶點擊。

3.通過CTA按鈕上的文字引導用戶
CTA按鈕上直觀的說服性的文字譬如“立即購買”也可以,但是“收為己有”卻很好地利用了人性的弱點——貪婪、欲望、占有心理,在看到自己喜歡的東西時,我們都希望這個東西是屬于自己的。

4.將星級評價放在屏幕中的顯著位置
屏幕中的顯著位置可以展示很多信息,將星級評分和評價放在這里絕對不會吃虧。因為好的評分和評論可以讓用戶很快知道商品的受歡迎程度,還可以幫商品在用戶心中建立權威;其次,將評價放在屏幕中的顯著位置可以讓用戶對商品留下一個好的印象。

5.在商品詳情頁添加社交分享按鈕,促進傳播
增加社交媒體按鈕不僅起到鼓勵用戶分享的作用,同時也便于用戶操作分享。我們一般主要用于分享當前頁面的商品。但其實,真正用于營銷推廣的分享并不應該僅限于商品本身。比如成功購買的記錄,或者是買家和賣家之間的互動評價,都可以成為分享的內容,這將比商品本身更有傳播性。

以上5點建議我們可以結合A/B測試來驗證,同時要確保我們采集的用戶行為數據精準有效。最后預祝各位電商小伙伴們雙十二大麥!
]]>
一個漂亮的平均數完全是用數據創造出來的虛幻景象,會給我們的決策造成誤導,因此我們需要掌握一個行之有效的方法來剖析真實的用戶行為和用戶價值,這個方法就是同期群分析(Cohort Analysis)。事實上,數據不會說謊,只是分析數據的人沒有做到精準分析而導致對數據呈現的錯誤解讀!
國內對同期群分析相關的研究相對較少,也許不是所有的運營都知道同期群分析,但它是每個產品運營必備的分析方法。在著名的《精益數據分析》一書里面,作為測試數據分析的靈魂也提到了同期群分析的相關內容。
同期群分析最早用于醫藥研究領域,意在觀察不同被試群體的行為隨著時間的變化呈現出怎么樣的不同。通過監測不同的被試群體,醫藥研究員可以觀察到不同的處方和治療方式對被試的影響并且確定被試共同的行為模式。 ]]>
一個漂亮的平均數完全是用數據創造出來的虛幻景象,會給我們的決策造成誤導,因此我們需要掌握一個行之有效的方法來剖析真實的用戶行為和用戶價值,這個方法就是同期群分析(Cohort Analysis)。事實上,數據不會說謊,只是分析數據的人沒有做到精準分析而導致對數據呈現的錯誤解讀!
國內對同期群分析相關的研究相對較少,也許不是所有的運營都知道同期群分析,但它是每個產品運營必備的分析方法。在著名的《精益數據分析》一書里面,作為測試數據分析的靈魂也提到了同期群分析的相關內容。
同期群分析最早用于醫藥研究領域,意在觀察不同被試群體的行為隨著時間的變化呈現出怎么樣的不同。通過監測不同的被試群體,醫藥研究員可以觀察到不同的處方和治療方式對被試的影響并且確定被試共同的行為模式。
那么在運營領域,什么是同期群呢?
同期群屬于用戶分群里的一個細分,是指在規定時間內對具有共同行為特征的用戶進行分群。“共同行為特征”是指在某個時間段內的相似行為,它除了按不同時間的新增用戶來分類外,還可以按不同的行為來分類,譬如“在2017年6月第一次購買”,“在2017年10月第二周對產品的使用頻率開始降低”等。
注意同期群分析側重于分析在客戶生命周期相同階段的群組之間的差異。
同期群分析(Cohort Analysis)為什么很重要?
在產品發展過程中,我們通常會把產品收入和產品用戶總量作為衡量這個產品成功與否的終極指標。不可否認這些指標固然重要,但是它們并不能用來衡量產品最近所取得的成功,并且極有可能會掩蓋一些急需我們關注的問題,如用戶參與度持續走低、用戶新增在逐漸變緩等。在分析用戶行為的過程中,我們需要更細致的衡量指標,這樣才更有利于我們準確預測產品發展的走向并通過版本迭代及時對產品進行優化和改進。
同期群分析(Cohort Analysis)是提高APP用戶留存的關鍵
上面提到,一個產品的成功與否不在于下載量多少,而在于如何留住即將流失的用戶以及如何召回已經流失的用戶。
我們不能通過下載量確定APP發展的具體情況,因為漂亮的下載數據會誤導我們以為APP發展很健康,但實際上,很多用戶下載幾天后就流失了。同期群分析是提高用戶留存的關鍵。
案例
針對首次啟動APP的用戶進行同期群分析,并觀察他們接下來七天的留存情況。
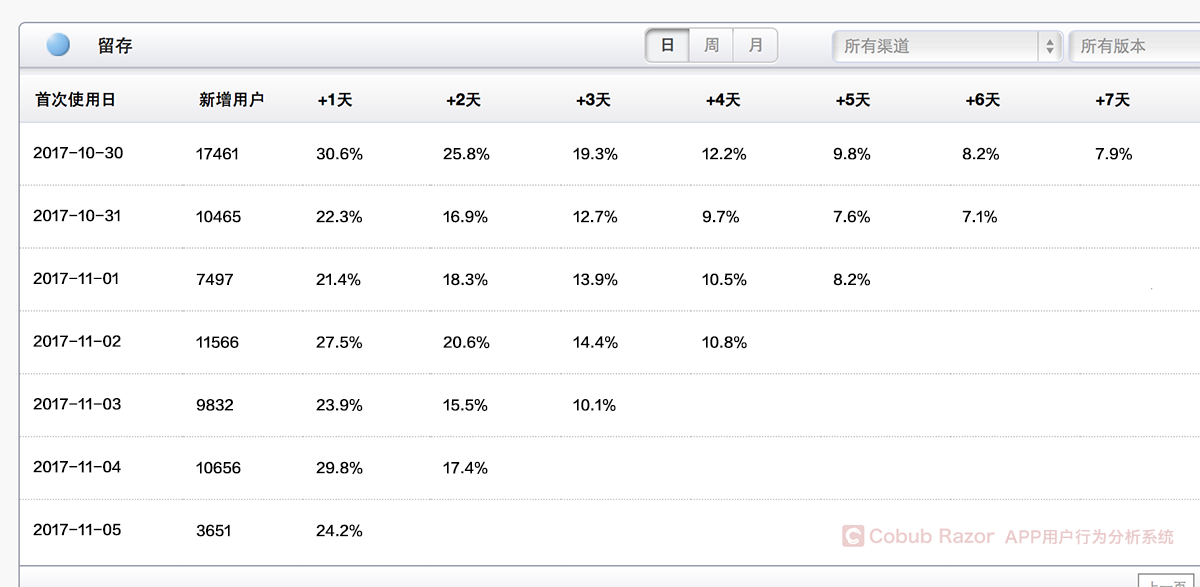
17461個新增用戶在10月30日首次啟動了APP,第一天在這些用戶里有 30.6%的人再次啟動,第四天12.2%,第七天7.9%,這表明在第七天的時候約每12個用戶里就只剩下一個活躍用戶。這同時也意味著我們流失了92%的用戶
我們需要知道哪些同期群有更好的留存并分析原因。如:我們在那一天發起了一場新的營銷活動嗎? 還是提供了促銷或折扣?或是發布了新功能,在產品里添加了視頻教程?我們可以將這些成功的策略應用于其他用戶,來提高用戶活躍度及留存率。我們還可以比較不同時間段的留存:
? 拉新后的留存:
通過比較拉新后不同的同期群,我們可以看到4天,7天等時間段后再次回來的用戶。這些同期群數據可以讓我們了解用戶登錄體驗,產品質量,用戶體驗,市場對產品的需求力等關鍵信息。
? 長期留存:
通過觀察每個同期群用戶再次回來使用APP的天數,我們可以看到每個同期群長期的留存,而不是拉新后幾天的留存。
我們可以知道用戶是在哪里退出的,并且可以知道活躍用戶群有什么特征,他們在做什么,這樣一方面有助于我們在拉新時快速找到目標用戶,另一方面我們還可以影響新用戶,讓他們遵循同樣的路線,最終成為忠誠用戶的模樣。
同期群分析(Cohort Analysis)能幫助我們實時監控真實的用戶行為、衡量用戶價值并制定有針對性的營銷方案
例如我們的運營團隊在9月份發起了一場為期60天的歡迎活動,想要通過一系列折扣和優惠來推動用戶增長。通過廣告展示和社交媒體,我們每天都有數以千計的用戶增長。5個月后,我們的用戶增長量非常大,領導對我們的活動結果非常滿意。
表面看,我們順利達到了用戶增長的目標。然而,當我們仔細研究同期群的數據,從用戶的終身價值出發,我們會發現,歡迎活動中新增的用戶在活動2個月之后購買率持續降低,與之相反,活動前的新增用戶如8月份的用戶,在活動的這五個月里購買率一直比較穩定。
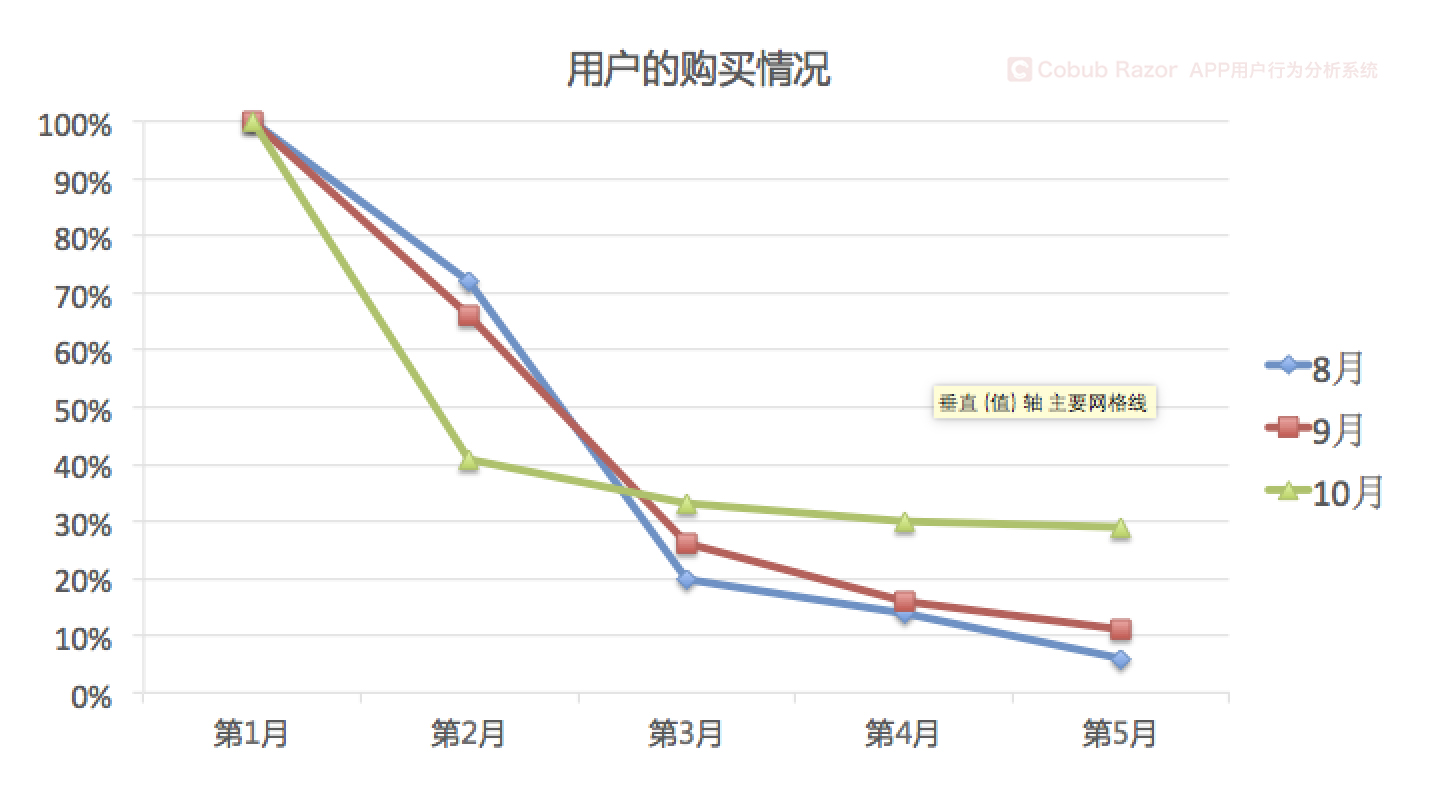
如果我們只把每月總收入作為衡量指標,我們就會以為收入增長僅僅來自新涌入的用戶。然而,活動啟動之后的用戶群組數據表明,一旦優惠活動結束,收入就會下降。收入下降證明我們并沒有擴大忠實用戶群體。
如上所示,通過同期群分析我們可以實時監控真實的用戶行為趨勢,否則,我們會因為只分析總體數據得到錯誤的判斷而做出錯誤的決策。通過分析每個同期群的行為差異,我們可以制定有針對性的營銷方案。在這個案例中,運營人員需要制定新策略來提高活動開始兩個月后的用戶參與度。
如何實施同期群分析(Cohort Analysis)?
首先從定義商業疑問開始
定義商業疑問是研究得到有效結果的前提。商業疑問定義基于商業目標以及研究試圖解決的問題。
用戶在我們優化產品之后購買轉化率是否提升?產品改進后用戶流失率是否降低?我們需要對這些疑問進行迭代和細化,以確保它與商業目標一致。
依據商業疑問定義度量指標
如購買轉化率和用戶留存率是回答業務問題的關鍵指標,我們想要了解從注冊到完成購買每一步的用戶流失率以及最后的購買轉化率。
定義同期群
前面留存的案例里,同期群是基于創建賬戶一周內購買的用戶。在其他情況下,我們可以用不同的方式定義同期群,例如,某個內容APP,我們可能會基于創建賬號的24小時內發布內容的用戶。
分析同期群數據
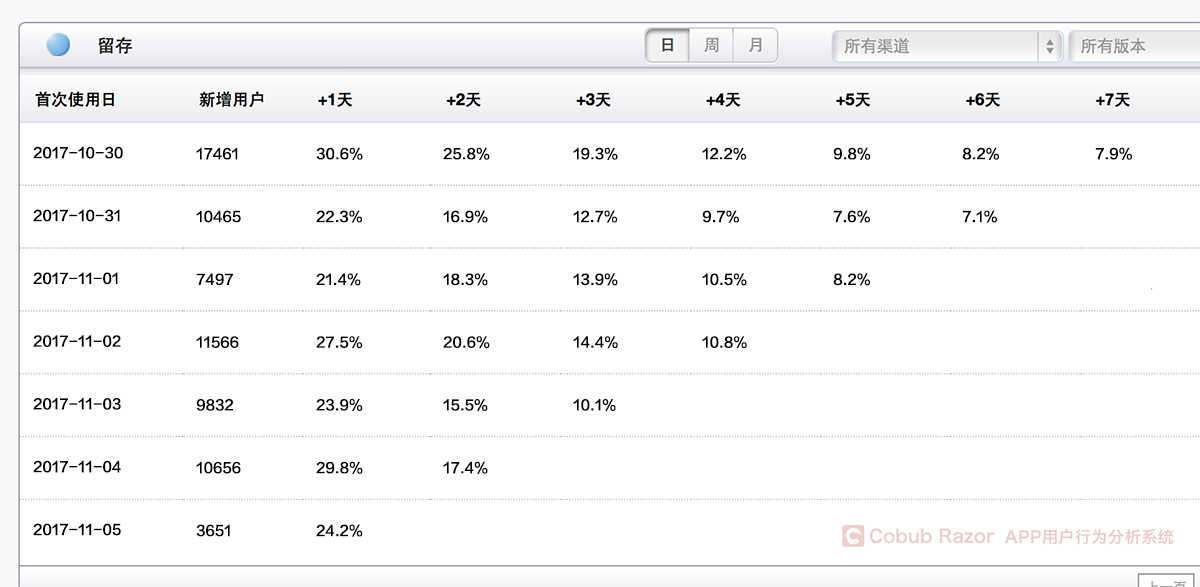
我們還以圖一典型的同期群表格為例,橫向為自然天數排列,縱向為每天的新增用戶數,表格內部是計算的每天留存率,一般情況下橫向的留存率最終會在某天后停留在一個相對穩定的狀態,從圖中我們可以看到,在第5天留存趨于穩定。這就說明這批用戶是穩定留存下來的。否則,如果留存率一直下降,總有一天會歸零。
我們再來看下縱向的留存數據,如果一個產品在健康發展,這個數據應該是越來越好。很顯然這個產品并不是,PM應該不斷根據歷史數據優化改進產品,提升用戶體驗,從而提高用戶留存率!
總結
同期群分析(Cohort Analysis)有利于我們更深層地分析用戶行為,并揭示總體衡量指標所掩蓋的問題。在營銷方式和活動效果不斷變化的當下,學會運用同期群分析有利于我們預測未來收入和產品發展趨勢。
]]>這種使用習慣到底是如何養成的?
為什么我們會習慣性地點開某個App?
為什么有些產品能讓我們戒不掉對它的癮,而其他的產品卻不行?
是否有什么秘訣能讓用戶對你的產品形成使用習慣,欲罷不能?

根據認知心理學家的界定,所謂習慣,就是一種“在情境暗示下產生的無意識行為”,是我們幾乎不假思索就做出的舉動。如今,我們習以為常的那些產品和服務正在改變我們的一舉一動,而這,正是產品設計者的初衷。也就是說,我們的行為已經在不知不覺中被設計了。
憑借電子屏幕上區區幾個編碼字符就能影響用戶的習慣、控制用戶的思維,這些公司是如何做到的?是什么因素讓人們對這些產品欲罷不能?
讓用戶養成習慣、產生依賴性,其實是很多產品不可或缺的一個要素。如今,越來越多的企業已經清醒地認識到,僅憑占有龐大的客戶群并不足以構成競爭優勢,用戶對產品高度的依賴性才是決定其經濟價值的關鍵。
那么,準備好了解更多有關培養積極的用戶習慣的內容了嗎?請接著往下看,你將對上癮模型獲取一份全新的認知。
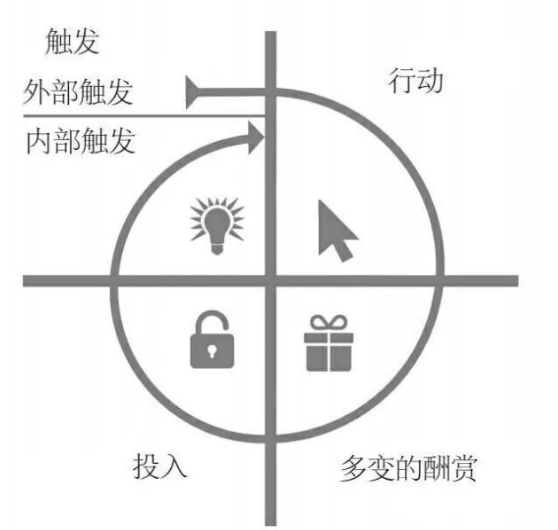
上癮模型的四個階段——觸發,行動,多變的酬賞,投入
觸發: 提醒人們采取下一步行動
觸發是上癮模型的第一階段,它可促使用戶觸發行動。觸發分為兩種:外部觸發和內部觸發。讓你產生習慣性依賴的那些產品往往是外部觸發最先發揮作用,它通過將信息滲透在你生活的方方面面來引導你采取下一步行動,例如電子郵件、網站鏈接,或是手機上的應用程序圖標。
使用外部觸發僅僅是邁出的第一步,內部觸發則是核心,它通過用戶記憶存儲中的各種關聯來提醒他們采取下一步行動,負面情緒往往可以充當內部觸發。開發習慣養成類產品的設計者需要揣摩用戶的心理,了解那些有可能成為內部觸發的各種情緒,并且要知道如何利用外部觸發來促使用戶付諸行動。

行動:人們在期待籌賞時的直接反應
觸發之后就是行動。如果他們沒有付諸行動,觸發就未能生效。斯坦福大學的福格博士認為,要讓人行動起來(Behave),三個要素必不可少:動機(M)、能力(A)、觸發(T)。用公式來表示,就是B=MAT。
觸發提醒你采取行動,而動機則決定你是否愿意采取行動。用戶產生使用產品的動機是基于人對于快樂的追求,對痛苦的逃避;對希望有追求,對恐懼有逃避。又因為人都渴望被認同,討厭被排斥。所以,只要你的產品能給用戶快樂,希望和認同,就相當于給了用戶行動的動機。
有了內心的“癢”(觸發),有了想撓癢癢的意愿(動機),還需要用戶能輕松“撓得到”。產品使用的難易程度會直接影響用戶對該產品的使用率。要想成功地簡化某個產品,我們就必須為用戶的使用過程掃清障礙。福格博士總結了影響任務難易程度的6個要素:完成這項活動所需的時間、經濟投入、體力、腦力、他人對該項活動的接受度,以及該項活動與常規活動之間的匹配程度或矛盾程度。在設計產品時,要弄清楚是什么原因阻礙了用戶完成這一活動。用戶究竟是沒時間,還是沒錢?是忙碌一天之后不想再動腦筋,還是產品太難操作?要贏得人心,你首先得讓自己的產品便捷易操作,讓用戶能夠輕松駕馭。
因此,要增加預想行為的發生率,觸發要顯而易見,行為要易于實施,動機要合乎常理。
多變的籌賞:滿足用戶的需求,激發使用欲
在第三階段,你的產品會因為滿足了用戶的需求而激起他們更強烈的使用欲。驅使用戶采取行動的,并不是酬賞本身,而是渴望酬賞時產生的那份迫切需要。上癮模型與普通反饋回路的區別在于,它可以激發人們對某個事物的強烈渴望。我們身邊的反饋回路并不少見,但是可以預見到結果的反饋回路無助于催生人們的內心渴望。
給產品“安裝”多變的酬賞,是公司用來吸引用戶的一個制勝法寶。從根本上講,多變的酬賞在吸引用戶的同時,必須滿足他們的使用需求。那些能秒殺用戶的產品或服務包含的酬賞往往不止一種。那些在多變性上不具備優勢的產品必須經常更新換代才能跟上時代的步伐。
社交籌賞
從產品中通過與他人的互動而獲取的人際獎勵。比如,小伙伴結婚的時候,發個朋友圈,收到了一波又一波的祝福,這就屬于社會化獎勵。我們喜歡我們的“圈子”,享受來自別人的點“贊”,期待他人的“評論”。社交酬賞會讓用戶念念不忘,并期待更多。
獵物獎勵
獲得資源或信息。比如微博,微博一開始吸引人們,是因為人們只要重復一個“滾動”的行為,就能搜索到自己喜歡的有趣信息,這就是狩獵獎勵機制,內容的多變性為用戶提供了不可預測的誘人體驗。
自我獎勵
體驗到的操控感、成就感和終結感。游戲中的“升級”影響的是自我對精通和能力的評價,升級、獲取特權等游戲規則都可以滿足玩家證明自己實力的欲望。甚至是平淡無奇的電子郵件,郵箱中未讀郵件的數量對很多人而言就像是任務,一項有待他們去完成的任務。
多變的酬賞是產品吸引用戶的一個有力工具。洞悉人們為何會對產品形成習慣性依賴,這有助于設計者投其所好地設計產品。
投入:通過用戶對產品的投入,培養“回頭客”
但是,僅僅依靠投其所好并不足以使產品在用戶心目中站穩腳跟。
一個一夜爆紅的產品,往往都有著很好的觸發,也有著易操作的行動,還有著豐富的社交酬賞。但是如果沒有后續引發長時間“投入”的能力,爆款也會隨著時間的推移而失去用戶的注意力。
事實證明,我們對事物的投入越多,就越有可能認為它有價值,也越有可能和自己過去的行為保持一致。最后,我們會改變自己的喜好以避免發生認知失調。這是上癮模型的最后一個階段,也是需要用戶有所投入的一個階段。投入階段與客戶對長期酬賞的期待有關,與及時滿足無關。
當用戶為某個產品提供他們的個人數據和社會資本,付出他們的時間、精力和金錢時,投入即已發生。話說回來,投入并不意味著讓用戶舍得花錢,而是指用戶的行為能提升后續服務質量。添加關注,列入收藏,壯大虛擬資產,了解新的產品功能,凡此種種,都是用戶為提升產品體驗而付出的投入。這些投入會對上癮模型的前三個階段產生影響,觸發會更易形成,行動會更易發生,而酬賞也會更加誘人。
你一定會說,一切皆有套路,那么知道了套路,如何反套路呢?
作為產品經理的你,可以利用上癮模型來比照一下自己的產品:
用戶真正需要什么?你的產品可以緩解什么痛苦?(內部觸發)
你靠什么吸引用戶使用你的產品?(外部觸發)
期待酬賞的時候,用戶可采取的最簡單的操作是什么?如何使該操作最簡化?(行動)
用戶是滿足于所得酬賞,還是想要更多酬賞?(多變的酬賞)
用戶對你的產品做出了哪些“點滴投入”?這些投入是否有助于加載下一個觸發,使產品質量在使用過程中獲得提升?(投入)
如果你是用戶,了解到這些“設計套路”,你就可以采取有針對性的“反設計、反套路”。檢視自己日常的一舉一動:哪些情景下,你會不自覺地點開某個App?什么時候最容易刷手機?其背后的驅動力是什么,是想打發時間,還是想舒緩壓力?通通記錄下來。找到自己的行為規律和內在驅動因素,才能有意識地掌控自己的行為。
文/ 小歐 微信公眾號:中歐國際工商學院
本文改編自《上癮:讓用戶養成使用習慣的四大產品邏輯》一書
1 Ambari簡介
Apache Ambari項目的目的是通過開發軟件來配置、監控和管理hadoop集群,以使hadoop的管理更加簡單。同時,ambari也提供了一個基于它自身RESTful接口實現的直觀、簡單易用的web管理界面。
Ambari允許系統管理員進行以下操作:
1. 提供安裝管理hadoop集群;
2. 監控一個hadoop集群;
3. 擴展ambari管理自定義服務功能.
1 Ambari簡介
Apache Ambari項目的目的是通過開發軟件來配置、監控和管理hadoop集群,以使hadoop的管理更加簡單。同時,ambari也提供了一個基于它自身RESTful接口實現的直觀、簡單易用的web管理界面。
Ambari允許系統管理員進行以下操作:
1. 提供安裝管理hadoop集群;
2. 監控一個hadoop集群;
3. 擴展ambari管理自定義服務功能.
2 集群所需基礎條件
2.1 操作系統的需求
? Red Hat Enterprise Linux (RHEL) 版本5.x 或者 6.x (64位) ;
? CentOS版本5.x、6.x (64位) 或7.x;
? Oracle Linux版本5.x 或者6.x (64位) ;
本文檔選擇的是CentOS版本 6.5 (64位) ;
2.2 系統基礎軟件的需求
在每一臺主機上都要安裝以下軟件:
(1) yum和rpm (RHEL/CentOS/Oracle Linux);
(2)zypper(SLES);
(3)scp,curl,wget;
2.3 JDK的需求
Oracle JDK 1.7.0_79 64-bit (默認)
OpenJDK 7 64-bit (SLES不支持)
3 安裝各項軟件前的先決條件
3.1 ambari和監控軟件所需條件
安裝ambari之前,為了保證ambari各項服務和各項監控服務的正常運行,根據操作系統的不同,需要確定一些已經安裝的軟件的版本,以下列出的軟件版本必須符合要求。即:如果現有的系統上有以下軟件,版本必須與下面列出的版本完全一致,如果沒有的話安裝程序會自行安裝。
圖表3-1軟件先決配置表


3.2 Ambari與HDP版本兼容性
由于軟件版本的升級,各版本之間由于版本之間的兼容性可能會導致一些問題。
表格 3-2 版本兼容性

4 安裝實例說明
本文所選擇的系統與軟件版本,如下表所示:
表格 4-1系統與軟件版本
![]()
4.1 安裝Ambari前的操作系統準備
4.1.1 配置主機名
Ambari配置集群信息的時候是通過全限定主機名來確定集群中的機器信息的,所以必須確保主機名無誤。
4.1.2 配置集群信息
在每一臺機器的hosts文件上都要做映射配置,命令如下:
# vi /etc/hosts
然后添加如下內容:
表格 4-2 ip映射信息表

4.1.3 配置ssh免密碼互通
首先,在主節點和其他節點上都執行以下命令,以確保每臺機器都可產生公鑰。
![]()
然后一路回車即可.然后將每個節點的公鑰組成一個新的authorized_keys文件,然后將其分發到每個節點中.從而,完成了各個節點的免密登錄操作.
4.1.4 配置NTP時間同步
首先在主節點上做如下操作:
(1) 安裝時間服務器ntp:
#yum install ntp
(2) 修改ntpd配置文件
(3) 開啟時間同步服務器
#sevrice ntpd start
(4) 在其他各個從節點做相同操作,至此ntp同步完成
4.1.5關閉selinux
永久關閉SELinux
# vi /etc/selinux/config
將SELINUX=enforcing改為SELINUX=disabled
重啟生效,重啟命令為:
# reboot
4.1.6關閉iptables防火墻
永久關閉(需要重啟)
# chkconfig iptables off
暫時關閉防火墻服務(需要重啟防火墻)
service iptables stop
查看防火墻狀態
# chkconfig –list|grep iptables
提示:Linux下的其它服務都可以用以上命令執行開啟和關閉操作
重啟生效,重啟命令為:
# reboot
4.2 創建yum本地源
首先檢驗主節點是否安裝httpd服務器,命令如下:
rpm -qa |grep httd
若沒有,則安裝,命令如下:
#yum install httpd
啟動httpd
#service httpd start
chkconfig httpd on
對文件夾與子文件夾內所有文件授予同一權限,命令如下:
chmod –R ugo+rX /var/www/html
打開網絡
vim /etc/sysconfig/network-script/ifcfg-eth0
修改為onboot=yes
安裝成功之后,Apache工作目錄默認在/var/www/html。
配置:
檢查端口是否占用,Apache http服務使用80端口
[root@master ~]$ netstat -nltp | grep 80
如果有占用情況,安裝完畢之后需要修改Apache http服務的端口號:
[root@ master ~]$ vi /etc/httpd/conf/httpd.conf
修改監聽端口,Listen 80為其他端口。
將所下載的安裝文件放在/etc/www/html下,然后啟動
[root@ master ~]$ service httpd start
可以在瀏覽器中查看http://master 看到Apache server的一些頁面信息,表示啟動成功。
5 完全離線安裝Ambari前的準備
離線安裝跟在線安裝的區別在于yum所使用的倉庫的位置不同,即把遠程的倉庫中的安裝包等資源拷貝一份兒放在本地,然后在yum倉庫包文件夾中創建這些資源的本地倉庫包,即可按照在線安裝的方式進行安裝就行了。不過離線安裝需要先解決Ambari的rpm包的依賴性問題,即首先要確保已經安裝了postgresql8.4.3,或者有本地postgresql8.4.3倉庫。
5.1 先決條件
Ambari的離線安裝,需要使用yum,如果是新安裝的操作系統,可能缺少很多必要的條件,以下表格按照從前往后的順序,依次說明,如果已經實現了某些條件,跳過那些條件即可。
因操作系統中本身自帶軟件的復雜性,如在安裝中提示有其他所需軟件或提示現有軟件升級,按照提示解決即可.
5.2 建立本地資源庫
在集群內部某臺機器上安裝http服務即可,然后將提供的tar包或者rpm包放置到那臺機器上的/var/www/html目錄(Apache默認目錄)下解壓即可,最好在這個目錄下新建一個目錄,將所有的ambari的tar包和HDP及HDPUTIL的tar包都放置進去并解壓,如果機器沒有手動安裝PostgreSQL,將提供的上述軟件的軟件包一并放入到本地資源庫中即可。
5.3 設置yum不檢查gpg密鑰
經檢測離線安裝Hadoop集群時會因為yum檢查要安裝的軟件的gpg密鑰而導致錯誤,此時可通過關閉系統的yum gpg檢查來規避錯誤
# vi /etc/yum.conf
設置gpgcheck屬性值為0即可
gpgcheck=0
5.4 安裝ambari服務
# yum –install ambari-server
5.5 ambari設置
# ambari-server setup
運行過后則會出現是否進入ambari-server守護進程,選擇jdk,配置數據庫等信息,可根據系統自身需要進行選擇.
當出現“Ambari Server ‘setup’ completed successfully”,則說明Ambari-server配置成功。需要說明的是,此次安裝選擇的數據庫是PostgreSQL數據庫,其中用戶、數據庫等都是提前默認好的;若選擇MySQL數據庫,則需要在安裝Ambari-server之前建好用戶、賦予權限、建好數據庫等等操作。
然后啟動ambari-server,最后根據需要安裝hadoop生態中的各項服務.
自定義service服務
1 ambari自定義擴展service
從第一部分可知,ambari具有進行二次開發的功能,主要工作就是將自研的組件等集成到ambari中,并對其進行管理監控.本文主要以集成redis為例進行講述.
首先,由于service都是隸屬于stack的,所以要決定自定義一個service屬于哪個stack.,又因為已經安裝了HDP2.5.0具有stack,所以,本文將自定的service放置在HDP2.5.0的stack下.新建service名為:redis-service,其中包含結構圖如下圖所示:

其中configurate中的xml文件主要安裝完成配置該模塊的調用,package中主要問控制service生命周期的python文件,metainfo.xml文件則主要問定義service的一些屬性,metrics.json與widgets.json控制著service的界面圖表顯示.
其中metainfo.xml實例如下:
2.0
REDIS-SERVICE
Reids
My Service
1.0
MASTER
Master
MASTER
redis
1
PYTHON
5000
SALVE
Slave
SLAVE
1+
PYTHON
5000
any
其次,需要創建 Service 的生命周期控制腳本master.py 和 slave.py。這里需要保證腳本路徑和上一步中 metainfo.xml 中的配置路徑是一致的。這兩個 Python 腳本是用來控制 Master 和 Slave 模塊的生命周期。腳本中函數的含義也如其名字一樣:install 就是安裝調用的接口;start、stop 分別就是啟停的調用;Status 是定期檢查 component 狀態的調用。其中master.py與slave.py的模板為:
Master.py
class Master(Script):
def install(self, env):
print "Install Redis Master"
def configure(self, env):
print "Configure Redis Master"
def start(self, env):
print "Start Redis Master"
def stop(self, env):
print "Stop Redis Master"
def status(self, env):
print "Status..."
if __name__ == "__main__":
Master().execute()
Slave.py
class Slave(Script):
def install(self, env):
print "Install Redis Slave"
def configure(self, env):
print "Configure Redis Slave"
def start(self, env):
print "Start Redis Slave"
def stop(self, env):
print "Stop Redis Slave"
def status(self, env):
print "Status..."
if __name__ == "__main__":
Slave().execute()
再次,將redis的rpm安裝文件放入到HDP安裝包的/var/www/html/ambari/HDP/centos6/目錄下.
再次,重啟ambari-server, 因為 Ambari Server 只有在重啟的時候才會讀取 Service 和 Stack 的配置。命令行執行:ambari-server restart.
最后,登錄 Ambari 的 GUI,點擊左下角的 Action,選擇 Add Service。如下圖:

此時就可以在安裝service列表中看到Redis服務了.然后檢驗該服務是否安裝成功.
2 ambari實現自定義擴展service界面顯示
在第二章的第一節中service自定義中提及metircs.json與widget.json時, 其中Widget 也就是 Ambari Web 中呈現 Metrics 的圖控件,它會根據 Metrics 的數值,做出一個簡單的聚合運算,最終呈現在圖控件中。Widget 則進一步提升了 Ambari 的易用性,以及可配置化。Widget 是顯示 AMS 收集的 Metrics 屬性.
此處緊接著上節,其中metrics.json模板為:
{
"REDIS-MASTER": {
"Component": [
{
"type": "ganglia",
"metrics": {
"default": {
"metrics/total_connections_received": {
"metric": "total_connections_received",
"pointInTime": true,
"temporal": true
},
"metrics/total_commands_processed": {
"metric": "total_commands_processed",
"pointInTime": true,
"temporal": true
},
"metrics/used_cpu_sys": {
"metric": "used_cpu_sys",
"pointInTime": true,
"temporal": true
},
"metrics/used_cpu_sys_children": {
"metric": "used_cpu_sys_children",
"pointInTime": true,
"temporal": true
}
}
}
}
]
}
}
widget.json為:
{
"layouts": [
{
"layout_name": "default_redis_dashboard",
"display_name": "Standard REDIS Dashboard",
"section_name": "REDIS_SUMMARY",
"widgetLayoutInfo": [
{
"widget_name": "Redis info",
"description": "Redis info",
"widget_type": "GRAPH",
"is_visible": true,
"metrics": [
{
"name": "total_connections_received",
"metric_path": "metrics/total_connections_received",
"service_name": "REDIS",
"component_name": "REDIS-MASTER"
}
],
"values": [
{
"name": "total_connections_received",
"value": "${total_connections_received}"
}
],
"properties": {
"graph_type": "LINE",
"time_range": "1"
}
}
}
至此,重啟ambari-service,命令如下:
ambari-server restart
3 數據采集及發送
利用shell腳本將redis運行信息數據采集并一次性發送到metrics collector中,腳本如下所示:
#!/bin/sh
url=http://$1:6188/ws/v1/timeline/metrics
while [ 1 ]
do
total_connections_received=$(redis-cli info |grep total_connections_received:| awk -F ':' '{print $2}')
total_commands_processed=$(redis-cli info |grep total_commands_processed:| awk -F ':' '{print $2}')
millon_time=$(( $(date +%s%N) / 1000000 ))
json="{
\"metrics\": [
{
\"metricname\": \"total_connections_received\",
\"appid\": \"redis\",
\"hostname\": \"localhost\",
\"timestamp\": ${millon_time},
\"starttime\": ${millon_time},
\"metrics\": {
\"${millon_time}\": ${total_connections_received}
}
},
{
\"metricname\": \"total_commands_processed\",
\"appid\": \"redis\",
\"hostname\": \"localhost\",
\"timestamp\": ${millon_time},
\"starttime\": ${millon_time},
\"metrics\": {
\"${millon_time}\": ${total_commands_processed}
}
}
]
}"
echo $json | tee -a /root/my_metric.log
curl -i -X POST -H "Content-Type: application/json" -d "${json}" ${url}
sleep 3
done
運行如下命令(這里要注意的是參數 1 是 Metrics Collector 的所在機器,并不是 Ambari Server所在的機器):
./metric_sender.sh ambari_collector_host total_connections_received redis
如果過程不出意外,等待2-4分鐘界面上即有數據顯示.通過上面的操作,可以實現將ambari沒有納入到監控管理的軟件進行管理監控。
如何讓消息推送達到我們預期的效果?APP運營人員必須密切關注用戶的行為習慣,對用戶的興趣偏好了然于胸,并針對不同的用戶群體在合適的時間推送給他們感興趣的內容。完美的推送消息推送對于用戶來講是有價值的,它能幫助產品提升用戶體驗,增加用戶好感度。
如何做到完美的消息推送?APP運營人員必須在推送之前確定以下5W法則:
Who: 推送對象
What: 推送內容
When: 推送時間
Where: 推送場景
Why: 推送原因
完美消息推送的5W法則,首發于Cobub。
]]>如何讓消息推送達到我們預期的效果?APP運營人員必須密切關注用戶的行為習慣,對用戶的興趣偏好了然于胸,并針對不同的用戶群體在合適的時間推送給他們感興趣的內容。完美的推送消息推送對于用戶來講是有價值的,它能幫助產品提升用戶體驗,增加用戶好感度。
如何做到完美的消息推送?APP運營人員必須在推送之前確定以下5W法則:
Who: 推送對象
What: 推送內容
When: 推送時間
Where: 推送場景
Why: 推送原因
厘清這5個W,我們推送的消息就是用戶所需要的!
1. Why: 我們為什么要推送這條消息?
“為什么”總是放在首位,每條推送消息都要有清晰的目標——讓用戶首次登陸還是讓用戶進行升級體驗?我們不僅要知道推送消息的目標,還需要明確我們期望從用戶那里獲得哪些行為數據。這些行為數據用來衡量推送消息對用戶造成的影響。例如,在用戶首次登錄某職場社交APP后,會收到如下圖的消息,這就是我們為了讓用戶完善個人資料而進行的推送。
2. What:我們要推送什么樣的內容?
推送消息的內容具有以下三個特點:
(1)具有針對性:
有時候一些小細節也能發揮出大作用。還是上面的例子,我們在給用戶推送歡迎消息的時候,在消息前加上用戶的名字,“Hi, XXX,歡迎…”,而不是籠統的直奔主題:“歡迎······…”,加上名字會讓用戶感覺更親切。
(2)確保相關性和及時性:
推送消息必須及時且和用戶高度相關。以網易新聞為例, 推送給用戶的是南京明晨的天氣消息,地理位置體現了相關性,此消息為周五下午推送,為用戶周六出行計劃給予參考提醒,時間恰到好處。

(3)準確快速地直達用戶痛點:
用戶的時間很寶貴,我們推送的消息一定要讓用戶獲得最大價值。不要給用戶推送垃圾消息,或者與用戶需求不相匹配的消息。例如,給沒有車的用戶推送代駕的消息。
3. Who: 我們要給誰推送消息?
推送消息對象不能一刀切,我們需要通過用戶行為數據對用戶進行分群管理,精細化運營。說到用戶行為,這里推薦幾個比較常用的用戶行為分析平臺,如:友盟、百度統計等。但這些SaaS平臺也有問題,原始數據做導出較為困難,自己產品的數據卻不能被我們自己擁有。推薦國內的開源私有化部署方案Cobub Razor,數據私有,后臺搭建也較為簡單。
不同的推送消息,接收對象也不同。
我們根據用戶的行為習慣、興趣偏好等不同,從用戶的需求出發,提供個性化的消息推送。例如一些音樂類APP針對用戶聽音樂的不同風格、喜愛的歌星以及收藏的歌單等推送相關的更新提醒,這樣的精準推送大大提高了用戶打開消息的比例。
4. 我們什么時候推送消息?
(1)一天中的時間:
可以選擇用戶空閑時間,如早上上班前,中午吃飯時,晚飯后,具體選擇哪個推送時間段,可以根據用戶使用應用的時段來確定,總之不要在用戶忙碌或者休息時打擾用戶。
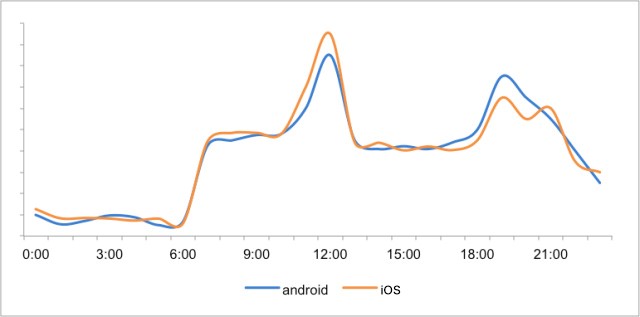
某金融app用戶使用時段
(2)推送頻率:
推送頻率過高會導致兩種結果——用戶點開推送消息后立馬關掉,或者用戶直接將消息忽略掉,看都不看一眼。推送頻率的多少要根據應用的類型而具體確定,一般來講,社交類App可每日推送,資訊類可一周3-4次、工具類一周1-2次。次數不宜過多,否則用戶不但不會打開,而且很可能關掉消息推送,甚至卸載應用。
(3)當地時間:
推送消息需要根據用戶的當地時間確定,這就需要我們根據用戶所在的地理位置來確定——如果你的用戶來自全球各地,那么北京時間下午四點的時候華盛頓是凌晨四點。如果我們統一以北京時間來推送消息,華盛頓的用戶就會被打擾。
5. Where: 我們在什么場景下推送消息?
推送場景也會影響推送消息產生的效果。我們需要考慮推送消息到達時用戶在哪里,他在干什么,或者用戶收到推送消息時用的什么設備等。
我們作為用戶每天都在接收著大量的推送,比如打車app會在周五下班時間段為我推送快車優惠券已入賬等消息;團購類app會在就餐時間推送給我附近餐廳的團購信息。如果用戶收到推送消息時處于被干擾的狀態,那么用戶就不會用心查看推送消息并采取我們期望的行動。

應用內的消息是根據用戶行為來推送,所以相對來說效果會更好一些。不管用戶吃飯、躺沙發,也不管用戶在PC端、移動端,只要我們清楚了解用戶行為,根據他們的行為推送相關消息,用戶就有很大可能采取我們期望的行動。
總結
完美的推送消息必須預先定義5W。通過5W,明確我們推送消息的目標、內容、對象、推送時間和場景,讓用戶看到推送消息帶給用戶的價值。推送是最好的用戶觸點,做一款貼心的符合用戶習慣的產品比天天掛在口頭的用戶體驗更為重要。
完美消息推送的5W法則,首發于Cobub。
]]>這幾年數據分析迅速發展,我們也做了一個微數據分析工具。該產品已成功運行三年,滿足日活百萬的企業。產品結構很簡單,用世上最簡單的語言php,最普遍的數據庫mysql,服務器可以選擇apache也可以選擇nginx,一切看你自己的喜好。
一、微服務架構圖:
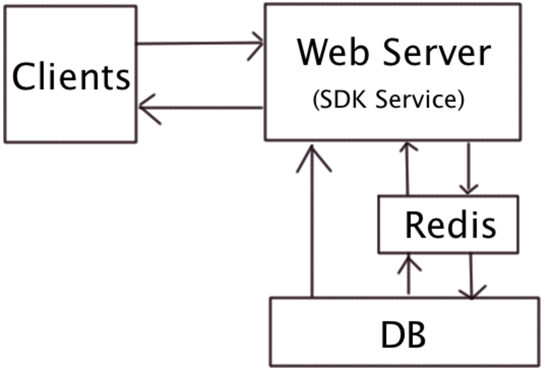
這幾年數據分析迅速發展,我們也做了一個微數據分析工具。該產品已成功運行三年,滿足日活百萬的企業。產品結構很簡單,用世上最簡單的語言php,最普遍的數據庫mysql,服務器可以選擇apache也可以選擇nginx,一切看你自己的喜好。
一、微服務架構圖
整個流程圖:
1、SDK上傳數據到服務器,如果安裝redis做緩存,數據會最先進到redis,然后定時抽取數據到DB服務器。有了redis可以大大提高并行數據處理能力。
2、數據庫收集原始數據,存儲過程將數據按照不同維度統計各個指標數據,同時將數據匯總表。
3、前臺報表展示,實時報表、小時報表和天報表數據展示。最好做到讀寫分離。
二、功能架構

功能架構主要包括功能、角色和權限三部分。功能是企業服務,用戶使用的每一個功能,就是企業的每一個服務。角色是用戶操作的歸類,功能與角色的對應關系及權限。了解系統架構的現狀,從功能架構開始。
三、應用架構
應用架構的內容包括現有架構圖、web應用現狀和接口架構。其中,接口是應用層面的關鍵,它是程序之間交互的部分。
主要包括clientdata、usinglog、event和errorlog等接口。
SDK通過接口定時發送數據到后臺。
應用架構羅列出前后端調用關系。
四、數據設計
兩個數據庫,大約一百張表。數據庫的設計依賴業務數據,對業務數據歸類,導致數據設計畫出E_R圖,數據設計完成,最終數據庫設計就出來了。數據庫只要早起設計的號,是可以做到易伸縮、易拆分的。統計類主要分為統計的維度,還有就是用戶、設備、錯誤信息等。
1、數據處理能力
日活百萬,啟動次數大概兩百萬,事件數和頁面訪問量起碼在三百到五百萬之間,平均每小時數據量五十萬。運行過程中,**客戶數據量集中在早晚高峰。根據客戶的特殊情況,會把一些任務安排在閑暇時間段,比如日任務、周任務、月任務等安排在零晨。
好的硬件配置是數據處理的好幫手,更大的內存更快的硬盤絕對可以讓數據流快速執行。
2、數據清洗和讀寫分離
大量原始數據入庫,這些數據處理之后就是垃圾數據了。當所有報表數據都統計之后并寫入各個維度表之后,需要定時把這些數據清除掉。
前臺報表展示數據跟存儲分析數據庫最好分開。
五、物理架構
微服務的物理架構需要的機器很少,一臺機器也能跑起來。分析統計主要是數據處理能力要求很高,數據庫服務器需要兩臺,web端需要一臺足矣。多年運營結果是并發和數據庫處理能力是統計分析的最大瓶頸。
六、繼續優化的方向
1、數據讀寫分離,數據清洗。
2、并發量。
七、客戶
客戶最關心的數據:
每一個客戶最關心的就是用戶表,用戶新增狀況、用戶活躍情況、用戶留存情況。
不同的客戶對用戶要求不同,需要判斷用戶是否是刷機來的,用戶跟設備號及用戶ID(用戶號碼)之間的映射關系。
事件數據也是很重要的,關系轉化率。
頁面訪問跟事件是同等重要。
錯誤數據可以檢測應用存在的Bug。
不同的客戶,不同的使用場景對指標會有不同需求。
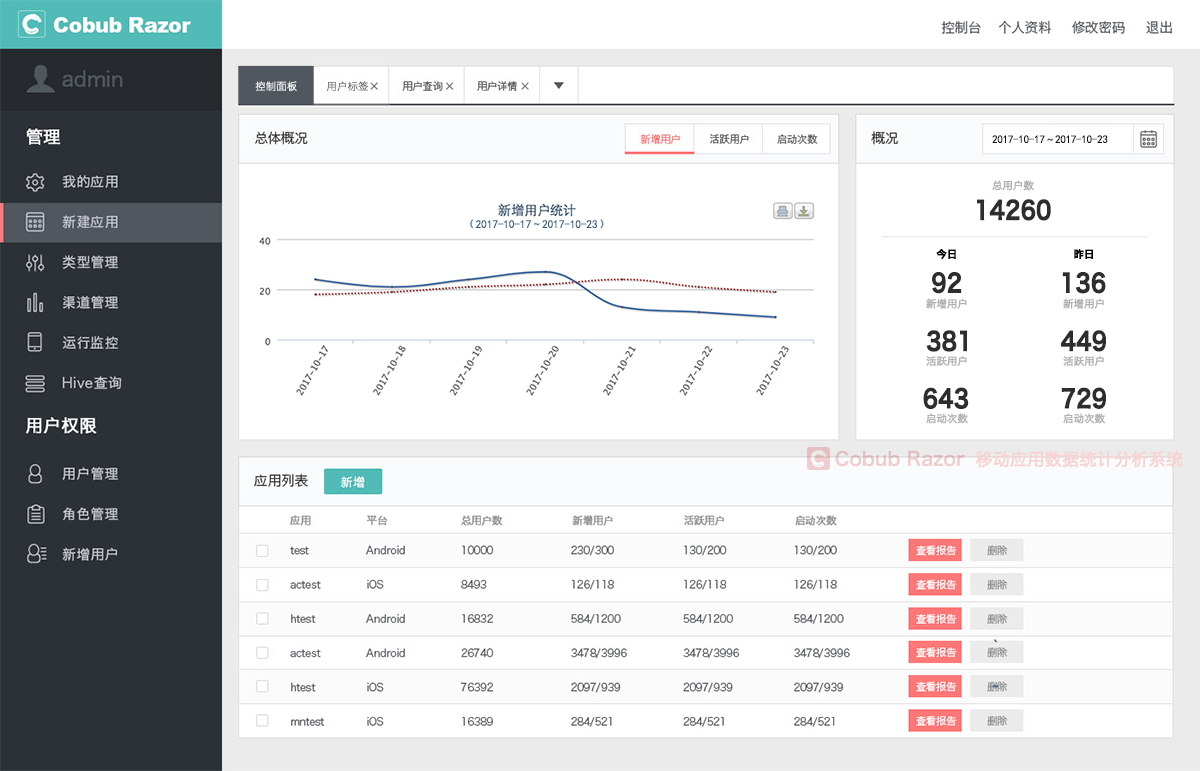
每個產品經理都知道數據分析很重要,但你能清晰地給出以下這兩個問題的答案嗎?
1. 數據分析到底是什么?
2. 數據分析為什么如此重要?
如果在這之前你不知道答案也沒關系,因為本文會圍繞以下幾點回答以上兩個問題:
1. 數據分析到底是什么?
2. 數據分析的相關概念
3. 如何實施數據分析?
4. 如何測量和收集數據?
5. 如何做數據分析報告?
6. 數據分析與產品的關系 ]]>
每個產品經理都知道數據分析很重要,但你能清晰地給出以下這兩個問題的答案嗎?
1. 數據分析到底是什么?
2. 數據分析為什么如此重要?
如果在這之前你不知道答案也沒關系,因為本文會圍繞以下幾點回答以上兩個問題:
1. 數據分析到底是什么?
2. 數據分析的相關概念
3. 如何實施數據分析?
4. 如何測量和收集數據?
5. 如何做數據分析報告?
6. 數據分析與產品的關系
數據分析到底是什么?
簡而言之,數據分析表征產品狀態、用戶行為和用戶所點擊的內容等等。雖然數據表征產品狀態,但它沒有表明產品所處狀態的原因。數據分析不能只靠單一的度量數據,應以一系列匯聚的度量數據為前提。
例如,如果我們要分析某個物體狀態,我們就不能只用物體溫度這個單一度量數據,只有結合其他諸如物體位置、速度、組成、環境溫度等一系列數據,我們才能實施分析。假設速度是0,物體位置離地面1米,周圍溫度與物體一樣,我們可以分析得出結論——物體處于靜止狀態。
同理,我們在分析產品狀態和用戶行為時,匯聚的度量數據越多,對我們越有利。
數據分析的相關概念
想要從數據分析中獲得最大價值,我們需要非常了解數據分析的相關概念。這些概念包括:
? 數據點
? 用戶分群
? 漏斗
? 時序分群
數據點
數據點,即數據的單獨點。數據點度量產品某個特定項目,包括度量數據和度量時間。
準確的數據點是我們繪制產品發展趨勢圖表的前提。
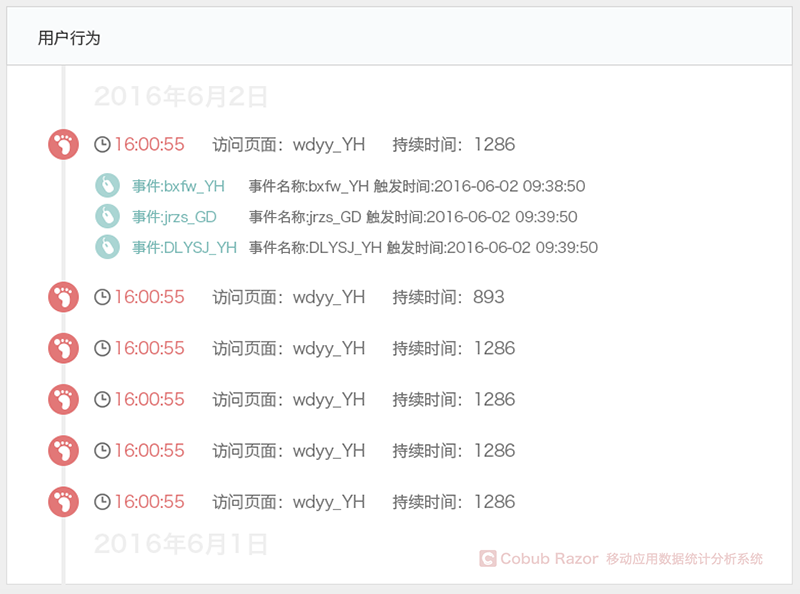
用戶分群
用戶分群的依據是用戶共同特征和產品使用模式。
用戶分群的依據包括但不限于:
? 技術方面(瀏覽器, 操作系統,設備等)
? 行為方面(初次訪問,回訪等)
? 人口統計學方面(語言,國家等)
在對用戶進行自定義分群時,我們需要依據可以度量的特征。例如,用戶性別就是可以度量的特征。只要我們在用戶個人資料里添加性別這一項,我們就可以采集到相關數據,這樣以性別作為分群依據就不難。
我們可以通過用戶分群了解用戶潛在的行為模式。數據平均值會掩蓋這些潛在行為模式。例如,雖然頁面平均訪問量是2,但是在添加了初次訪問vs回訪這個細分特征之后,我們發現初次訪問者的平均頁面瀏覽量是1.2,而回訪者的平均頁面瀏覽量是3.4。如果不進行用戶分群,初訪者和回訪者頁面瀏覽量的差異就會被頁面瀏覽量的平均值所掩蓋。
通過用戶分群,我們可以把數據分析重點集中在主要目標用戶群體。例如,我們的主要目標用戶分布在華東地區,只要區分華東各省市用戶群體并重點分析這些地域的用戶行為,就可以優化產品以適應他們的需求,而不是針對全國用戶進行產品優化。
漏斗模型
漏斗模型主要用于流量監控、產品目標轉化等日常數據運營與數據分析工作。
為了達到目的,用戶會執行一系列操作。例如,在電商平臺上,用戶為了實現購買的目的,會執行以下操作:
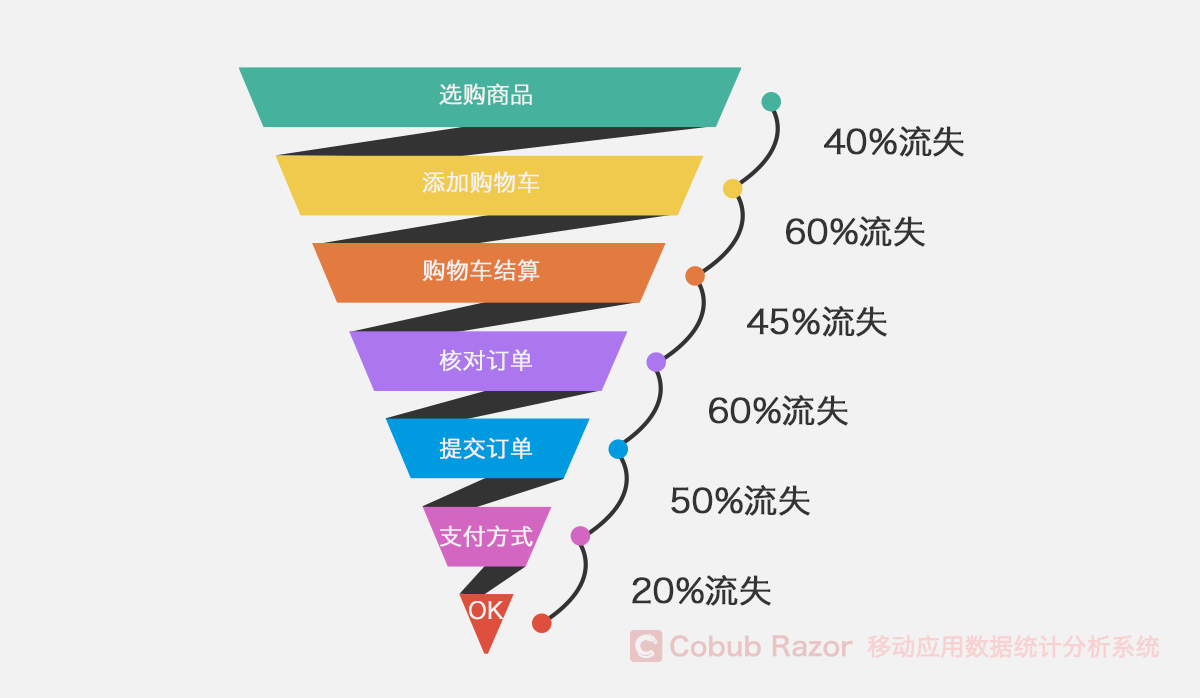
通過漏斗模型,我們可以知道用戶在哪一步流失,從而通過調查分析找出用戶流失原因。
時序分群
時序分群與用戶分群類似,區別是時序分群的目的是比較分析用戶行為隨著時間的變化。
時序分群有利于我們衡量用戶長期價值。
時序分群之后可以進行不同的比較,例如,我們可以比較一周前的注冊用戶和一個月前的注冊用戶,也可以比較某個特定日期的注冊用戶。如果我們沒有針對一周前和一個月前的用戶進行分群,那么新進來的用戶會干擾我們分析這兩個時間段的用戶行為。對某個特定時間段的用戶進行比較時,我們可以衡量某個營銷活動或者產品某個功能更新后對用戶行為產生的影響。
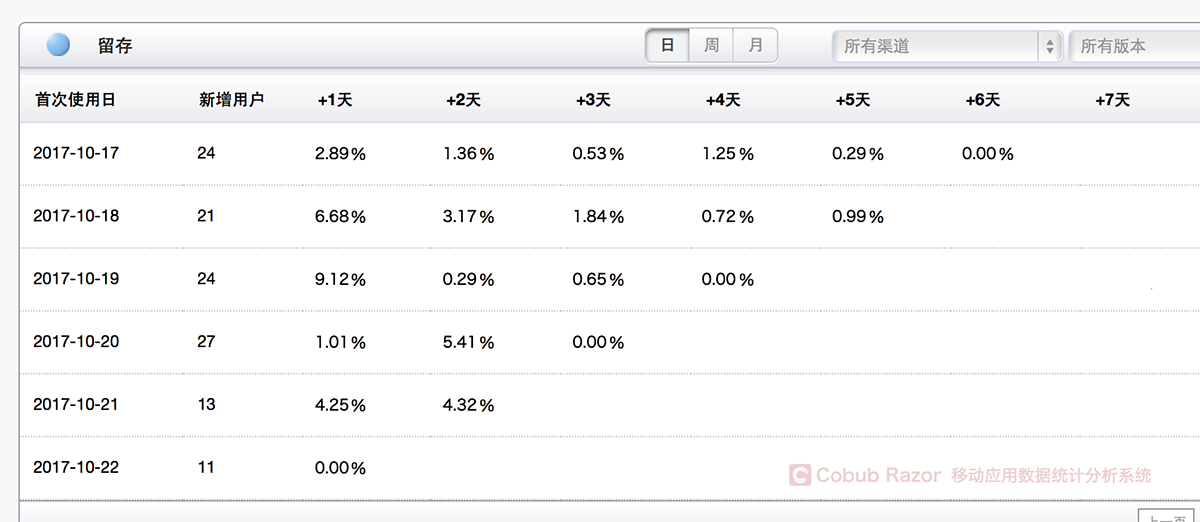
上圖是一個基于用戶注冊時間的留存圖。與其他用戶群相比,十月八日這一天的用戶留存顯著增加。當我們看到這個數據時我們可以探索是什么導致了用戶留存的改變。
如何實施數據分析?
產品經理會接觸到海量的數據,那么我們應該如何實施數據分析?我們需要制定如下計劃:
1. 定義產品愿景
2. 定義滿足產品愿景的KPI
3. 定義允許我們達到KPI的度量指標
4. (通過用戶行為日志)定義影響度量的漏斗
為了更好地制定計劃,我們需要了解計劃里的相關概念。
產品愿景
產品愿景指產品用途和目標用戶,簡而言之,“產品為用戶解決了什么問題?”沒有產品愿景,我們接下來的所有行動都是浪費時間。
KPI
KPI衡量產品表現。拉新,留存,活躍,轉化等這些都屬于KPI的范疇。我們還可以用KPI制定產品發展目標,譬如將用戶注冊量提高20%或者將購買轉化率提高30%。KPI要適合產品所處階段,如果我們剛開始創業,那么主要KPI就是用戶注冊量,而不是用戶活躍度。
度量指標
度量指標是達成KPI的手段。度量指標一般有轉化率,購買率等等。通過計算兩個或多個數據點,我們可以得到度量指標數據。同時,度量指標的變化趨勢也是產品改進的依據。
漏斗
重要的漏斗會以某種方式改變度量指標。在確立產品使用流程/用戶行為日志后,我們依據度量指標和用戶行為制定相關漏斗模型。以注冊率為度量指標和以轉化率為度量指標所制作的漏斗模型不可能相同。
獲得數據點
獲得可測量的數據點對達成KPI, 計算度量指標數據,制作漏斗意義重大。
計劃并非一成不變,我們需要根據產品愿景、KPI等適時更新計劃。
如何采集和統計數據?
方法有兩種:建立內部分析系統,或者依賴第三方的分析系統。
內部分析系統可以根據度量指標進行定制開發。缺點是我們需要耗費資源單獨建立和維護。
外部分析系統,譬如Google Analytics, Mixpanel, KISSmetrics等都是不錯的選擇。第三方的分析系統易于實現且不會浪費建立和維護所需要的資源。Cobub Razor是國內一款專業的APP數據統計分析工具,支持私有化部署,數據既靈活又安全,是個不錯的選擇。
如何做數據分析報告?
通常我們通過制作比較圖表和趨勢圖表來做數據分析報告。
比較圖表體現某個度量指標在兩個時間點之間的變化,比如某個度量指標在上個星期和這個星期之間的變化。它讓我們看到兩個時間點之間度量指標是否有較大的波動。
趨勢圖表體現某個度量指標在一段時間內的變化,例如某個度量指標在過去一個月內的變化。它顯示度量指標的變化方向,指明產品表現——變好、變差還是保持不變?
報告定位出問題,然后通過嘗試回答“為什么XX會發生?”“為什么YY會改變?”這些問題,我們可以優化和改進產品。
數據分析與產品的關系
我們依據數據分析結果改進產品。如果沒有數據分析,我們容易盲目改變產品,拍腦袋決策;如果沒有數據分析,我們也不能知道產品改變之后所產生的效果。在產品發展的過程中,我們需要不斷地進行數據分析,以保證產品按照我們的期望發展。
為了保證產品處于領先狀態,產品經理必須知道數據分析是什么以及數據分析的重要性。希望本文能對廣大產品經理有所幫助。