第一張暹羅
 ]]>
]]>第一張暹羅
第二張英短

你以后是不是可以識別了暹羅和英短了?大概能,好像又不能。這是因為素材太少了,我們看這兩張圖能分別提取出來短特征太少了。那如果我們暹羅短放100張圖,英短放100張圖給大家參考,再給一張暹羅或者英短短照片是不是就能識別出來是那種貓了,即使不能完全認出來,是不是也有90%可能是可以猜猜對。那么如果提供500張暹羅500張英短短圖片呢,是不是猜對的概率可以更高?
我們是怎么識別暹羅和英短的呢?當然是先歸納兩種貓的特征如面部顏色分布、眼睛的顏色等等,當再有一張要識別短圖片時,我們就看看面部顏色分布、眼睛顏色是不是可暹羅的特征一致。
同樣把識別暹羅和英短的方法教給計算機后,是不是計算機也可以識別這兩種貓?
那么計算機是怎么識別圖像的呢?先來看一下計算機是怎么存儲圖像的。
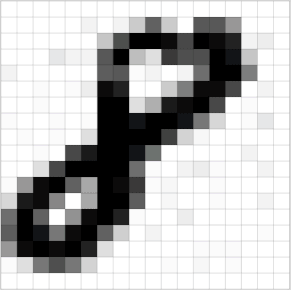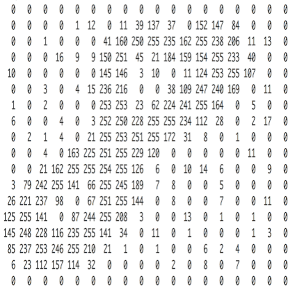
圖像在計算機里是一堆按順序排列的數字,1到255,這是一個只有黑白色的圖,但是顏色千變萬化離不開三原色——紅綠藍。
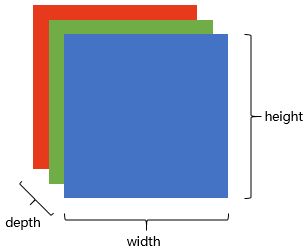
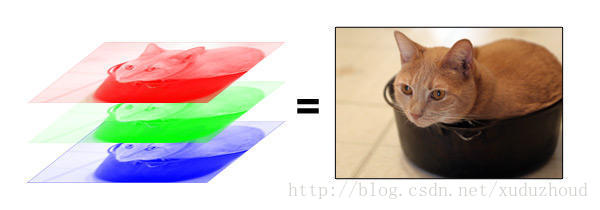
這樣,一張圖片在計算機里就是一個長方體!depth為3的長方體。每一層都是1到255的數字。
讓計算機識別圖片,就要先讓計算機了解它要識別短圖片有那些特征。提取圖片中的特征就是識別圖片要做的主要工作。
下面就該主角出場了,卷及神經網絡(Convolutional Neural Network, CNN).
最簡單的卷積神經網絡就長下面的樣子。
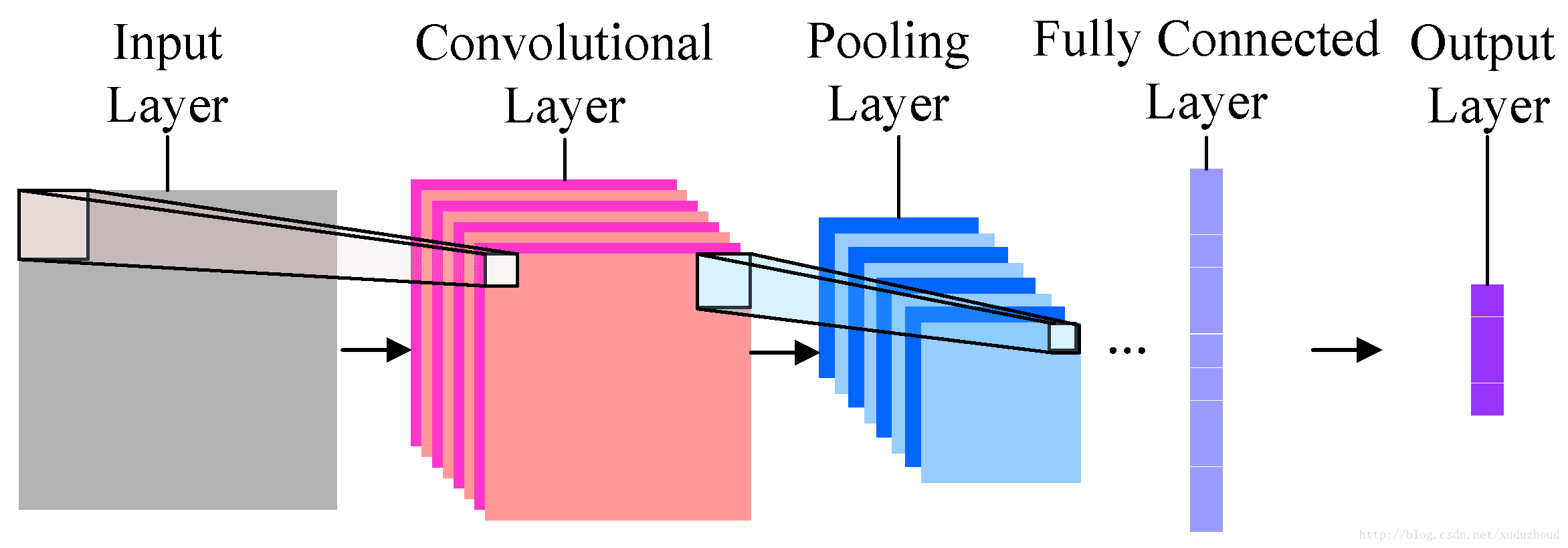
分為輸入、卷積層、池化層(采樣層)、全連接和輸出。每一層都將最重要的識別信息進行壓縮,并傳導至下一層。
卷積層:幫助提取特征,越深(層數多)的卷積神經網絡會提取越具體的特征,越淺的網絡提取越淺顯的特征。
池化層:減少圖片的分辨率,減少特征映射。
全連接:扁平化圖片特征,將圖片當成數組,并將像素值當作預測圖像中數值的特征。
?卷積層
卷積層從圖片中提取特征,圖片在計算機中就上按我們上面說的格式存儲的(長方體),先取一層提取特征,怎么提取?使用卷積核(權值)。做如下短操作:
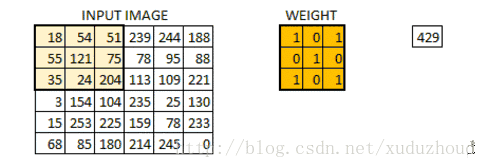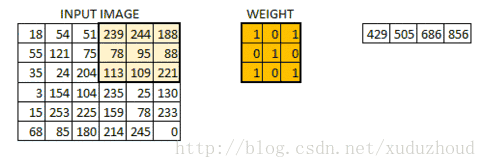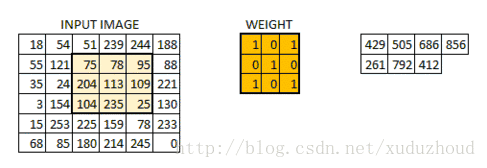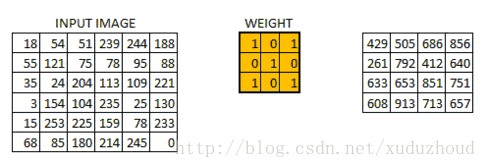
觀察左右兩個矩陣,矩陣大小從6×6 變成了 4×4,但數字的大小分布好像還是一致的。看下真實圖片:

圖片好像變模糊了,但這兩個圖片大小沒變是怎么回事呢?其實是用了如下的方式:same padding
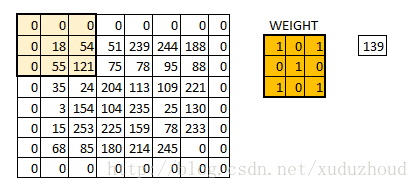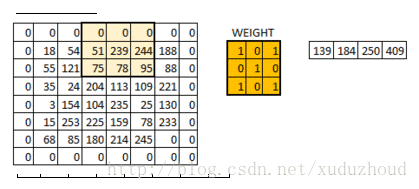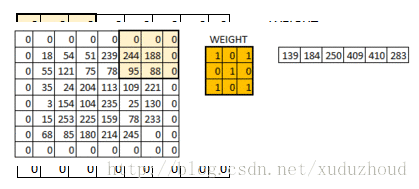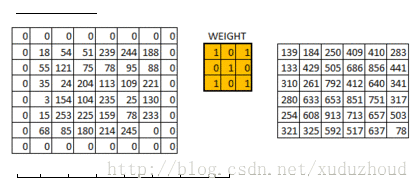
在6×6的矩陣周圍加了一圈0,再做卷積的時候得到的還是一個6×6的矩陣,為什么加一圈0這個和卷積核大小、步長和邊界有關。自己算吧。
上面是在一個6×6的矩陣上使用3X3的矩陣做的演示。在真實的圖片上做卷積是什么樣的呢?如下圖:

對一個32x32x3的圖使用10個5x5x3的filter做卷積得到一個28x28x10的激活圖(激活圖是卷積層的輸出).
?池化層
減少圖片的分辨率,減少特征映射。怎么減少的呢?
池化在每一個縱深維度上獨自完成,因此圖像的縱深保持不變。池化層的最常見形式是最大池化。
可以看到圖像明顯的變小了。如圖:
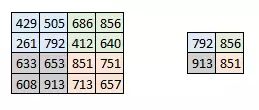
在激活圖的每一層的二維矩陣上按2×2提取最大值得到新的圖。真實效果如下:
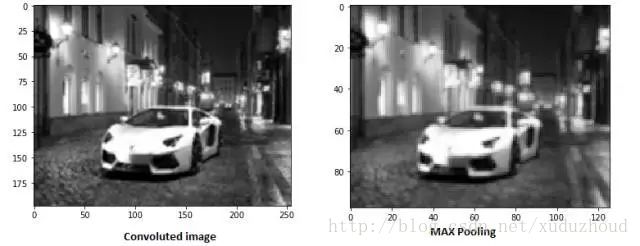
隨著卷積層和池化層的增加,對應濾波器檢測的特征就更加復雜。隨著累積,就可以檢測越來越復雜的特征。這里還有一個卷積核優化的問題,多次訓練優化卷積核。
下面使用apple的卷積神經網絡框架TuriCreate實現區分暹羅和英短。(先說一下我是在win10下裝的熬夜把電腦重裝了不下3次,系統要有wls,不要用企業版,mac系統和ubuntu系統下安裝turicreae比較方便)
首先準備訓練用圖片暹羅50張,英短50長。測試用圖片10張。
上代碼:(開發工具anaconda,python 2.7)


數據放到了h盤image目錄下,我是在win10下裝的ubuntu,所以h盤掛在mnt/下。
test的文件:(x指暹羅,y指英短,這樣命名是為了代碼里給測試圖片區分貓咪類型)

test_data[‘label’] = test_data[‘path’].apply(lambda path: ‘xianluo’ if ‘x’ in path else ‘yingduan’)
第一次結果如下:
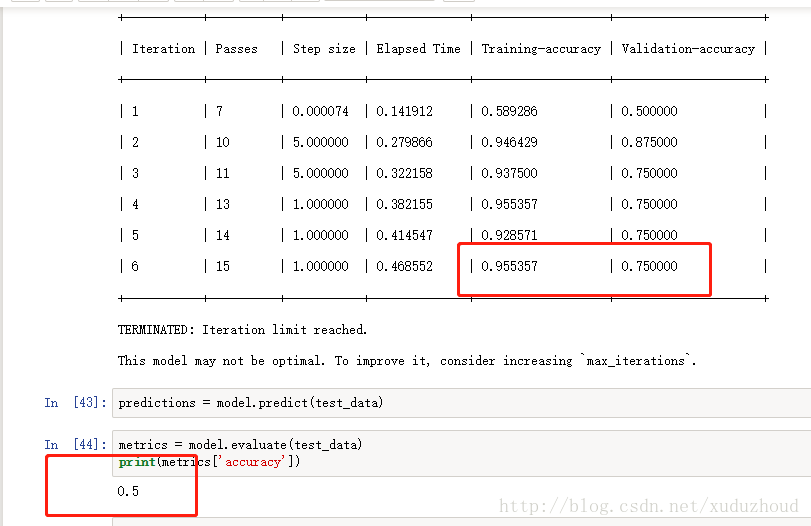
訓練精度0.955 驗證精度才0.75 正確率才0.5。好吧,看來是學習得太少,得上三年高考五年模擬版,將暹羅和英短的圖片都增加到100張。在看結果。
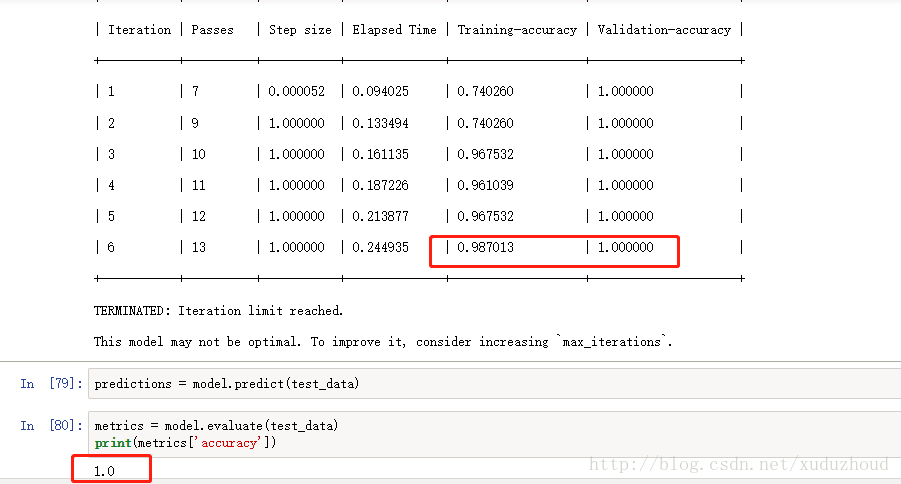
這次訓練精度就達到0.987了,驗證精度1.0,正確率1.0 牛逼了。
看下turicreate識別的結果:
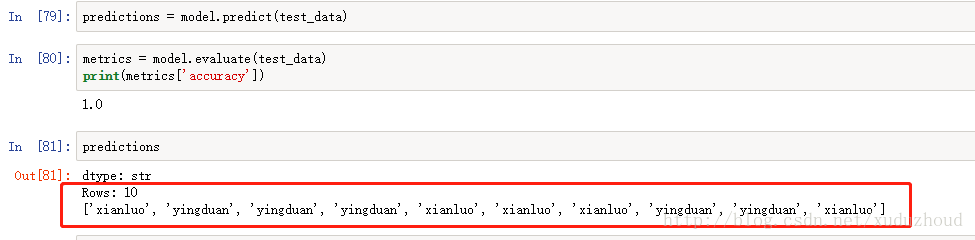
我們實際圖片上貓是:(紅色為真實的貓的類型-在代碼里根據圖片名稱標記的,綠色為識別出來的貓的類型)
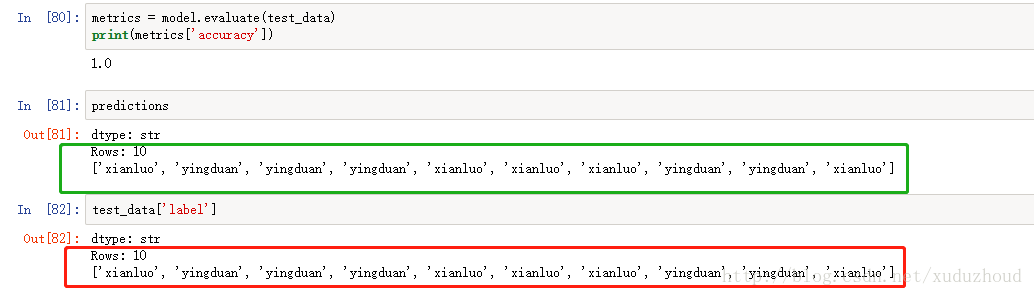
可以看到兩者是一致的。牛逼了訓練數據才兩百張圖片,就可以達到這種效果。 ]]>
一個月離職,一般是不能適應工作或與工作內容本身有關。
半年的情況,一般與直接上級有關。
2年以上離職,基本上屬于認可公司,但發展受限
其實對于產品留存也和員工入職相似,短期留存、中期留存和長期留存的緣由大有不同。 ]]>
一個月離職,一般是不能適應工作或與工作內容本身有關。
半年的情況,一般與直接上級有關。
2年以上離職,基本上屬于認可公司,但發展受限
其實對于產品留存也和員工入職相似,短期留存、中期留存和長期留存的緣由大有不同。
01
短期留存來講,可以理解為用戶初步了解產品之后的留存,也就是說產品下載后用了一下,并沒有馬上刪掉或者近兩天選擇刪掉。
新用戶一般在app下載完成之后會進入直接的了解產品階段,這個階段,在產品主要功能界面,如果產品本身沒有什么特別顯眼的亮點(可以理解為撩點),或者一下子勾住用戶的東西,用戶流失的可能性很大,畢竟大部分用戶只是嘗鮮的狀態,這類流失問題,一般智能(算法)或精選推薦類的內容型的產品有優勢,資訊類的也好,短視頻的也好,商城類的也好,直播類的也好,能夠采用高度的熱點內容推薦勾住大部分用戶的使用欲。
比如我最近在嘗試了解的抖音,他有很大的優勢決定了app的短期留存率會高于其他同類短視頻,原因有三,第一:抖音本身的音樂屬性和產品用戶定位決定了他的視頻更有特點;第二:抖音的拍攝門檻、制作高標準和視頻處理的優勢,決定了視頻的高質量;第三,首頁精選機制,讓用戶的選擇門檻降低,我們打開APP就能播放短視頻,并且從我幾天的觀看情況來看,質量都挺高。(我目前沒找到抖音首頁的推薦算法相關內容,但是從內容質量上來講,應該有較大的人工干預機制)。

抖音的這三個特點決定了用戶在打開app后,能快速的沉浸在高質量的短視頻中,也就是能快速的勾住用戶,這一點我會覺得強于快手,快手在短視頻的選擇上,是一件很費力的事情。你回憶下你在某個無聊的下午,想看找一部好電影看看,篩選電影過程中的糾結與吐槽。
而對于沒有抖音這類有鮮明特點的內容產品來講,可以從另外一個角度出發。根據頭條發布的 2016 移動資訊行業細分報告,今日頭條娛樂興趣用戶占全平臺總量 68.29%,占比排名第一。占比第二是的社會類資訊,達 67.29%,占比第三的是搞笑類,占46.56%。也就是說只是集合了這三點,那么對于嘗鮮用戶推薦,短期上的留存率會極高。
當然對非內容型產品,一般的采用的是強視覺和交互的形式,也就是說,采用用戶能一眼看懂產品的側重點,產品的使用特點,讓用戶能很容易的上手,也就是快速形成這個產品很品質不低,這個產品功能看起來挺好的第一觀感。
這也就能理解為什么對于很多新產品來講,一個好的新手引導非常重要了,這是對于用戶快速了解產品的一個捷徑。新手引導可能不僅包含產品的功能的使用,還包括產品的核心亮點呈現(可能包括一些理念,比如匠心、高品質之類的內容介紹)。
02
對于中期來講,更加合適的內容和更加舒適的功能使用變得是比較重要的。任何一個東西,我們都會從驚艷期(或嘗鮮期)逐步過渡到平和期,當我們已經習慣了產品的大部分功能的時候,把產品的功能做的更細膩,更便捷,比如,更了解當前用戶,推薦算法更精確;比如,操作更便捷,將原有的三步點擊變為一步,就像我們使用電腦時間長了,很多功能我們會傾向于使用快捷鍵而非鼠標;再比如,提供更加個性的視覺方案,app換設計風格,也就是說這個是一個從產品還不錯到用的爽的步驟。
網易云音樂的歌曲評論模塊,這個本身并不是一個很剛需的功能,但是作為錦上添花的功能效果卻非常的棒,很多置頂的評論直接帶動了用戶的情緒,加強了歌曲本身的感染力。

再往前進一步,提供更加有趣的內容哪怕是跟產品核心功能弱關聯。網易云音樂的“朋友”模塊,我發現我曾經無意識的花了大量的時間在上面,里面有有趣的短視頻,搞怪的gif動畫,好聽的音樂,還有一些明星小八卦,本身來講這個模塊跟音樂并沒有太直接的關系,但是他從聽音樂的人和明星出發,以朋友圈的形式(當然他的推薦機制并非朋友圈這種,而是帶有智能和熱點推薦的機制在其中,畢竟云音樂的朋友關系大多是弱關系,和微信略有差異),作為云音樂的留存模塊,這個我覺得是作為中期留存是可以借鑒的。
03
再說說長期,也就是資深用戶的留存問題,當用戶習慣了產品的內容和功能,其實會有一個“癢”的階段,微信做的再好,用了一兩年之后,你可能會覺得不過如此,幽默段子看多了,你經常能猜出一些套路,幽默也就變成了無聊了。papi醬你現在還看嗎,用很多網友的話說,就那些套路,再說下抖音,他現在也有這樣的問題,抖音從音樂短視頻出發,也就是說很多視頻會在固定的音樂節奏和內容中,這就決定了他的很多視頻拍攝和剪輯套路相同,我周圍有不少深度使用的用戶都說視頻重復率過高,經常能看到類似的形式,新鮮感逐漸遞減。
在這個階段,一般的產品會祭出三張大旗,第一個叫社交,第二個叫用戶成長體系,第三個叫持續的運營刺激(包括形式多變的話題、熱點、社群)。
社交好理解,我們之所以不放棄微信,是因為上面有我們大量的社會關系,我們關注的并不是微信,而是微信上的人,只是目前沒有一個產品能做到微信這樣的強關系鏈特質。
直播的yy直播、陌陌,短視頻類的快手、抖音,在產品的新鮮度遞減的情況下,可不能建立微信這種強關系,但是弱關系依然是有強大的挖掘的可能。
直播也好,短視頻也好,作為孤獨和無聊出口的一個方向,我們可以通過屏幕看到一個個有趣的陌生人,既然是人,那么自然就有人格。
那么弱關系的挖掘可以從內容的喜好變為人格的喜歡,這個可以理解為與AKB48類似的養成,不同點在于,也許我以前是喜歡你的優秀的作品,后面成為粉絲后我喜歡的是你作為人的個性與有趣,那么作品只是你人格的組成部分,在后期,你關注的那個主播可能不需要非常亮眼的內容,你甚至會更加喜歡,覺得他真實。
這就是內容型產品社交弱關系的可深度挖掘的部分。
成長體系,簡單來說,就是“工作幾年之后榮譽以及一些特權、福利”,這個不做細講,展開來非常大。
持續的運營刺激,一般分為兩種情況,資訊、媒體類產品一般傾向于制造爭議話題的運營,話題內容往往能出其不意,畢竟并非一家之言,選題選的好,可能下面的回復會爆點不斷。
商城類產品會傾向于,制造節日,雙十一也好,618也好,都屬于這一類,當然持續的運營刺激,制造節日屬于規律性的,也有非規律性的,比如滴滴、膜拜的毫無理由的送券,送優惠。
04
總結下,我說的雖然是短中長期的留存,但這個短中長并非一個特定的時長,不同用戶對產品使用的程度不同,反映的各個用戶身上的短中長期流程的時間也可能不一樣。這是其一。
二是,我說的這些產品功能內容并非一定要分先后,有可能同時并行研發,畢竟有的留存功能是三個階段都適用的,只是說哪個階段的效果最佳而已,低層本高產出,做最有效率的事情。
就像一個剛畢業的大學生,你給他講再高質量的500強企業商戰干貨,對他來講,并沒有什么卵用,還不如教他如何提高面試成功率比較實在。留存的方案策略使用也是如此。
以上是留存方面的一點小思考,希望有用。
內容轉載自公眾號 油炸果子
]]>1 Ambari簡介
Apache Ambari項目的目的是通過開發軟件來配置、監控和管理hadoop集群,以使hadoop的管理更加簡單。同時,ambari也提供了一個基于它自身RESTful接口實現的直觀、簡單易用的web管理界面。
Ambari允許系統管理員進行以下操作:
1. 提供安裝管理hadoop集群;
2. 監控一個hadoop集群;
3. 擴展ambari管理自定義服務功能.
1 Ambari簡介
Apache Ambari項目的目的是通過開發軟件來配置、監控和管理hadoop集群,以使hadoop的管理更加簡單。同時,ambari也提供了一個基于它自身RESTful接口實現的直觀、簡單易用的web管理界面。
Ambari允許系統管理員進行以下操作:
1. 提供安裝管理hadoop集群;
2. 監控一個hadoop集群;
3. 擴展ambari管理自定義服務功能.
2 集群所需基礎條件
2.1 操作系統的需求
? Red Hat Enterprise Linux (RHEL) 版本5.x 或者 6.x (64位) ;
? CentOS版本5.x、6.x (64位) 或7.x;
? Oracle Linux版本5.x 或者6.x (64位) ;
本文檔選擇的是CentOS版本 6.5 (64位) ;
2.2 系統基礎軟件的需求
在每一臺主機上都要安裝以下軟件:
(1) yum和rpm (RHEL/CentOS/Oracle Linux);
(2)zypper(SLES);
(3)scp,curl,wget;
2.3 JDK的需求
Oracle JDK 1.7.0_79 64-bit (默認)
OpenJDK 7 64-bit (SLES不支持)
3 安裝各項軟件前的先決條件
3.1 ambari和監控軟件所需條件
安裝ambari之前,為了保證ambari各項服務和各項監控服務的正常運行,根據操作系統的不同,需要確定一些已經安裝的軟件的版本,以下列出的軟件版本必須符合要求。即:如果現有的系統上有以下軟件,版本必須與下面列出的版本完全一致,如果沒有的話安裝程序會自行安裝。
圖表3-1軟件先決配置表


3.2 Ambari與HDP版本兼容性
由于軟件版本的升級,各版本之間由于版本之間的兼容性可能會導致一些問題。
表格 3-2 版本兼容性

4 安裝實例說明
本文所選擇的系統與軟件版本,如下表所示:
表格 4-1系統與軟件版本
![]()
4.1 安裝Ambari前的操作系統準備
4.1.1 配置主機名
Ambari配置集群信息的時候是通過全限定主機名來確定集群中的機器信息的,所以必須確保主機名無誤。
4.1.2 配置集群信息
在每一臺機器的hosts文件上都要做映射配置,命令如下:
# vi /etc/hosts
然后添加如下內容:
表格 4-2 ip映射信息表

4.1.3 配置ssh免密碼互通
首先,在主節點和其他節點上都執行以下命令,以確保每臺機器都可產生公鑰。
![]()
然后一路回車即可.然后將每個節點的公鑰組成一個新的authorized_keys文件,然后將其分發到每個節點中.從而,完成了各個節點的免密登錄操作.
4.1.4 配置NTP時間同步
首先在主節點上做如下操作:
(1) 安裝時間服務器ntp:
#yum install ntp
(2) 修改ntpd配置文件
(3) 開啟時間同步服務器
#sevrice ntpd start
(4) 在其他各個從節點做相同操作,至此ntp同步完成
4.1.5關閉selinux
永久關閉SELinux
# vi /etc/selinux/config
將SELINUX=enforcing改為SELINUX=disabled
重啟生效,重啟命令為:
# reboot
4.1.6關閉iptables防火墻
永久關閉(需要重啟)
# chkconfig iptables off
暫時關閉防火墻服務(需要重啟防火墻)
service iptables stop
查看防火墻狀態
# chkconfig –list|grep iptables
提示:Linux下的其它服務都可以用以上命令執行開啟和關閉操作
重啟生效,重啟命令為:
# reboot
4.2 創建yum本地源
首先檢驗主節點是否安裝httpd服務器,命令如下:
rpm -qa |grep httd
若沒有,則安裝,命令如下:
#yum install httpd
啟動httpd
#service httpd start
chkconfig httpd on
對文件夾與子文件夾內所有文件授予同一權限,命令如下:
chmod –R ugo+rX /var/www/html
打開網絡
vim /etc/sysconfig/network-script/ifcfg-eth0
修改為onboot=yes
安裝成功之后,Apache工作目錄默認在/var/www/html。
配置:
檢查端口是否占用,Apache http服務使用80端口
[root@master ~]$ netstat -nltp | grep 80
如果有占用情況,安裝完畢之后需要修改Apache http服務的端口號:
[root@ master ~]$ vi /etc/httpd/conf/httpd.conf
修改監聽端口,Listen 80為其他端口。
將所下載的安裝文件放在/etc/www/html下,然后啟動
[root@ master ~]$ service httpd start
可以在瀏覽器中查看http://master 看到Apache server的一些頁面信息,表示啟動成功。
5 完全離線安裝Ambari前的準備
離線安裝跟在線安裝的區別在于yum所使用的倉庫的位置不同,即把遠程的倉庫中的安裝包等資源拷貝一份兒放在本地,然后在yum倉庫包文件夾中創建這些資源的本地倉庫包,即可按照在線安裝的方式進行安裝就行了。不過離線安裝需要先解決Ambari的rpm包的依賴性問題,即首先要確保已經安裝了postgresql8.4.3,或者有本地postgresql8.4.3倉庫。
5.1 先決條件
Ambari的離線安裝,需要使用yum,如果是新安裝的操作系統,可能缺少很多必要的條件,以下表格按照從前往后的順序,依次說明,如果已經實現了某些條件,跳過那些條件即可。
因操作系統中本身自帶軟件的復雜性,如在安裝中提示有其他所需軟件或提示現有軟件升級,按照提示解決即可.
5.2 建立本地資源庫
在集群內部某臺機器上安裝http服務即可,然后將提供的tar包或者rpm包放置到那臺機器上的/var/www/html目錄(Apache默認目錄)下解壓即可,最好在這個目錄下新建一個目錄,將所有的ambari的tar包和HDP及HDPUTIL的tar包都放置進去并解壓,如果機器沒有手動安裝PostgreSQL,將提供的上述軟件的軟件包一并放入到本地資源庫中即可。
5.3 設置yum不檢查gpg密鑰
經檢測離線安裝Hadoop集群時會因為yum檢查要安裝的軟件的gpg密鑰而導致錯誤,此時可通過關閉系統的yum gpg檢查來規避錯誤
# vi /etc/yum.conf
設置gpgcheck屬性值為0即可
gpgcheck=0
5.4 安裝ambari服務
# yum –install ambari-server
5.5 ambari設置
# ambari-server setup
運行過后則會出現是否進入ambari-server守護進程,選擇jdk,配置數據庫等信息,可根據系統自身需要進行選擇.
當出現“Ambari Server ‘setup’ completed successfully”,則說明Ambari-server配置成功。需要說明的是,此次安裝選擇的數據庫是PostgreSQL數據庫,其中用戶、數據庫等都是提前默認好的;若選擇MySQL數據庫,則需要在安裝Ambari-server之前建好用戶、賦予權限、建好數據庫等等操作。
然后啟動ambari-server,最后根據需要安裝hadoop生態中的各項服務.
自定義service服務
1 ambari自定義擴展service
從第一部分可知,ambari具有進行二次開發的功能,主要工作就是將自研的組件等集成到ambari中,并對其進行管理監控.本文主要以集成redis為例進行講述.
首先,由于service都是隸屬于stack的,所以要決定自定義一個service屬于哪個stack.,又因為已經安裝了HDP2.5.0具有stack,所以,本文將自定的service放置在HDP2.5.0的stack下.新建service名為:redis-service,其中包含結構圖如下圖所示:

其中configurate中的xml文件主要安裝完成配置該模塊的調用,package中主要問控制service生命周期的python文件,metainfo.xml文件則主要問定義service的一些屬性,metrics.json與widgets.json控制著service的界面圖表顯示.
其中metainfo.xml實例如下:
2.0
REDIS-SERVICE
Reids
My Service
1.0
MASTER
Master
MASTER
redis
1
PYTHON
5000
SALVE
Slave
SLAVE
1+
PYTHON
5000
any
其次,需要創建 Service 的生命周期控制腳本master.py 和 slave.py。這里需要保證腳本路徑和上一步中 metainfo.xml 中的配置路徑是一致的。這兩個 Python 腳本是用來控制 Master 和 Slave 模塊的生命周期。腳本中函數的含義也如其名字一樣:install 就是安裝調用的接口;start、stop 分別就是啟停的調用;Status 是定期檢查 component 狀態的調用。其中master.py與slave.py的模板為:
Master.py
class Master(Script):
def install(self, env):
print "Install Redis Master"
def configure(self, env):
print "Configure Redis Master"
def start(self, env):
print "Start Redis Master"
def stop(self, env):
print "Stop Redis Master"
def status(self, env):
print "Status..."
if __name__ == "__main__":
Master().execute()
Slave.py
class Slave(Script):
def install(self, env):
print "Install Redis Slave"
def configure(self, env):
print "Configure Redis Slave"
def start(self, env):
print "Start Redis Slave"
def stop(self, env):
print "Stop Redis Slave"
def status(self, env):
print "Status..."
if __name__ == "__main__":
Slave().execute()
再次,將redis的rpm安裝文件放入到HDP安裝包的/var/www/html/ambari/HDP/centos6/目錄下.
再次,重啟ambari-server, 因為 Ambari Server 只有在重啟的時候才會讀取 Service 和 Stack 的配置。命令行執行:ambari-server restart.
最后,登錄 Ambari 的 GUI,點擊左下角的 Action,選擇 Add Service。如下圖:

此時就可以在安裝service列表中看到Redis服務了.然后檢驗該服務是否安裝成功.
2 ambari實現自定義擴展service界面顯示
在第二章的第一節中service自定義中提及metircs.json與widget.json時, 其中Widget 也就是 Ambari Web 中呈現 Metrics 的圖控件,它會根據 Metrics 的數值,做出一個簡單的聚合運算,最終呈現在圖控件中。Widget 則進一步提升了 Ambari 的易用性,以及可配置化。Widget 是顯示 AMS 收集的 Metrics 屬性.
此處緊接著上節,其中metrics.json模板為:
{
"REDIS-MASTER": {
"Component": [
{
"type": "ganglia",
"metrics": {
"default": {
"metrics/total_connections_received": {
"metric": "total_connections_received",
"pointInTime": true,
"temporal": true
},
"metrics/total_commands_processed": {
"metric": "total_commands_processed",
"pointInTime": true,
"temporal": true
},
"metrics/used_cpu_sys": {
"metric": "used_cpu_sys",
"pointInTime": true,
"temporal": true
},
"metrics/used_cpu_sys_children": {
"metric": "used_cpu_sys_children",
"pointInTime": true,
"temporal": true
}
}
}
}
]
}
}
widget.json為:
{
"layouts": [
{
"layout_name": "default_redis_dashboard",
"display_name": "Standard REDIS Dashboard",
"section_name": "REDIS_SUMMARY",
"widgetLayoutInfo": [
{
"widget_name": "Redis info",
"description": "Redis info",
"widget_type": "GRAPH",
"is_visible": true,
"metrics": [
{
"name": "total_connections_received",
"metric_path": "metrics/total_connections_received",
"service_name": "REDIS",
"component_name": "REDIS-MASTER"
}
],
"values": [
{
"name": "total_connections_received",
"value": "${total_connections_received}"
}
],
"properties": {
"graph_type": "LINE",
"time_range": "1"
}
}
}
至此,重啟ambari-service,命令如下:
ambari-server restart
3 數據采集及發送
利用shell腳本將redis運行信息數據采集并一次性發送到metrics collector中,腳本如下所示:
#!/bin/sh
url=http://$1:6188/ws/v1/timeline/metrics
while [ 1 ]
do
total_connections_received=$(redis-cli info |grep total_connections_received:| awk -F ':' '{print $2}')
total_commands_processed=$(redis-cli info |grep total_commands_processed:| awk -F ':' '{print $2}')
millon_time=$(( $(date +%s%N) / 1000000 ))
json="{
\"metrics\": [
{
\"metricname\": \"total_connections_received\",
\"appid\": \"redis\",
\"hostname\": \"localhost\",
\"timestamp\": ${millon_time},
\"starttime\": ${millon_time},
\"metrics\": {
\"${millon_time}\": ${total_connections_received}
}
},
{
\"metricname\": \"total_commands_processed\",
\"appid\": \"redis\",
\"hostname\": \"localhost\",
\"timestamp\": ${millon_time},
\"starttime\": ${millon_time},
\"metrics\": {
\"${millon_time}\": ${total_commands_processed}
}
}
]
}"
echo $json | tee -a /root/my_metric.log
curl -i -X POST -H "Content-Type: application/json" -d "${json}" ${url}
sleep 3
done
運行如下命令(這里要注意的是參數 1 是 Metrics Collector 的所在機器,并不是 Ambari Server所在的機器):
./metric_sender.sh ambari_collector_host total_connections_received redis
如果過程不出意外,等待2-4分鐘界面上即有數據顯示.通過上面的操作,可以實現將ambari沒有納入到監控管理的軟件進行管理監控。
無碼埋點的實現流程
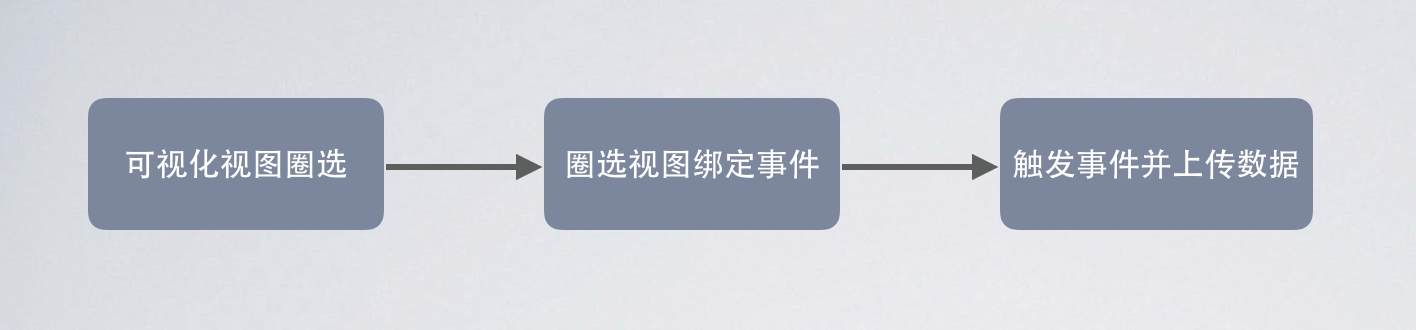
1.可視化視圖圈選,在頁面上會出現浮動的圓圈,拖動圓圈至想配置事件的控件上,將會彈出輸入事件的彈框。
2.在上一步的彈框中輸入自定義的事件名稱,名稱將會和視圖的viewPath綁定起來。viewPath是視圖的唯一標識,在下文中將詳細講解。
3.用戶點擊了控件,判斷控件是否綁定過事件,如綁定則進行事件上傳。
實現流程中的技術點
可視化視圖圈選實現
自定義UIWindow的子類,當做懸浮小圓圈,添加UIPanGestureRecognizer手勢,根據手勢的位移,設置懸浮框的位移。手勢停止時獲取懸浮窗中心點的坐標。
遍歷主window上的子視圖,找到包含上述懸浮窗中心點且能響應用戶交互的最里層視圖,即為用戶可以圈選的視圖。
參考iOS控件的消息傳遞鏈,有個核心方法。UIView hitTest:(CGPoint)point withEvent:(UIEvent *)event。此API自動遍歷子視圖,找到包含point的視圖,event傳nil。由于event參數是nil,最終找到的視圖并不一定是能響應用戶手勢的視圖,如果不能響應則遍歷其父視圖,直到找到能響應用戶行為的視圖。
圈選視圖綁定事件
視圖唯一標識viewPath生成,上述步驟已經拿到了圈選的視圖。如何確定視圖的viewPath也是重點。viewPath需要整個應用唯一,才可以區別不同的事件。由于是無碼,所以只能從視圖本身的屬性去分析。我們可以把App的視圖結構理解成樹的概念,樹的根節點是UIWindow,樹的枝干由UIViewController和UIView組成,葉子節點都是UIView。那么從根節點到葉子節點的路徑可以看做是唯一的。也就是視圖的viewPath。下面介紹下實現的邏輯,viewPath由兩部分組成,第一部分是節點路徑,另一部分是與之對應的節點index。節點路徑是由每個節點的Class拼接而成,節點index,就是節點在父節點中的下標,比如子視圖在父視圖的subviews數組中的下標。下圖是遍歷節點的邏輯圖。
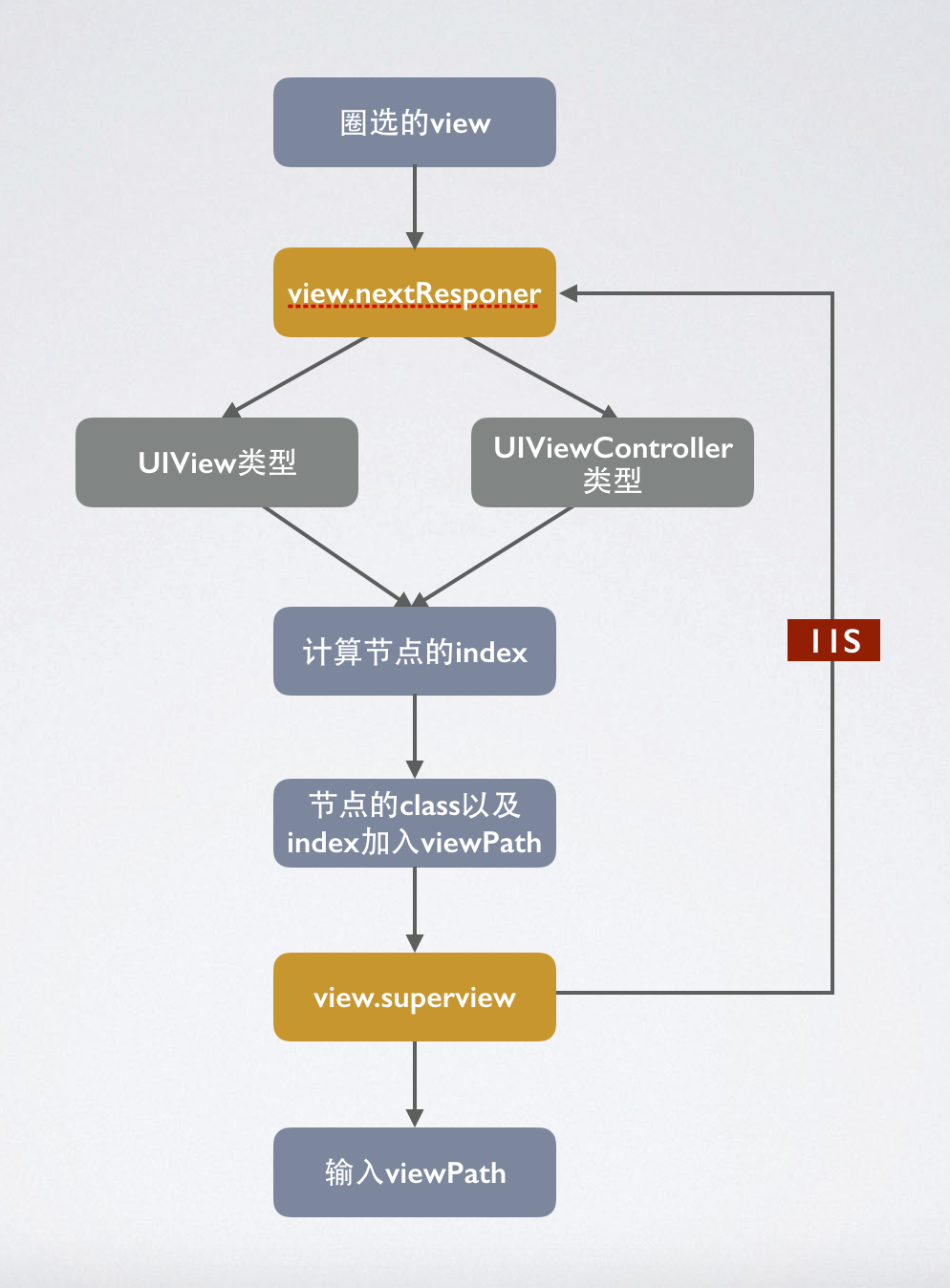
計算節點的index,這個步驟,有種特殊的視圖需要注意,可復用視圖的index是跟數據源相關的,比如UITableViewCell,此類視圖的index不能使用父視圖的subviews的下標代替,應該使用數據源的下標代表,比如cell的indexPath.section:indexPath.row。下面給出一個簡單視圖和可復用視圖的viewPath的例子。TestViewController-UIView-UIButton&0-0-0和TableViewController-UITableView-UITableViewCell&0-0-1:0。
如何檢測用戶觸發了綁定了事件ID的視圖也是重點,此處運用的核心技術是runtime中Method Swizzle。下面介紹一下針對不同類型的控件,如何hook相應的方法。
1. UIControl類型的控件hook – (void)sendAction:(SEL) to:(id)target forEvent:(UIEvent *)event
2. UIScrollView,UITextView,UITableView,UICollectionView 類型的控件,先hook -(void)setDelegate:(id
3. 帶手勢事件的視圖 hook -(void)addGestureRecognizer方法,并在方法實現中給手勢對象添加新的target和action ,- (void)addTarget:(id)target action:(SEL)action。
總結
無碼埋點的關鍵技術,就是以上分析的幾點,首先通過可視化圈選拿到需要綁定事件視圖,并生成唯一標識viewPath,通過hook系統控件的方法,拿到用戶觸發的視圖,生成視圖的viewPath與本地的事件列表比對,比對成功則上傳viewPath對應的事件。
]]>這幾年數據分析迅速發展,我們也做了一個微數據分析工具。該產品已成功運行三年,滿足日活百萬的企業。產品結構很簡單,用世上最簡單的語言php,最普遍的數據庫mysql,服務器可以選擇apache也可以選擇nginx,一切看你自己的喜好。
一、微服務架構圖:
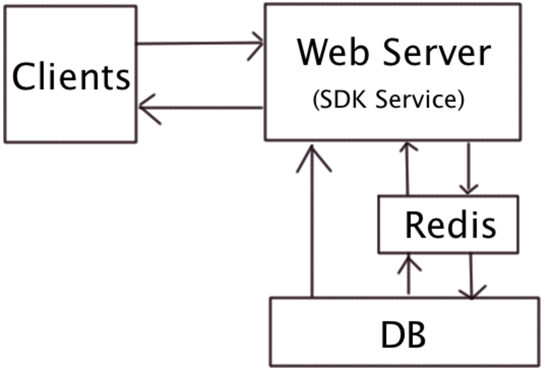
這幾年數據分析迅速發展,我們也做了一個微數據分析工具。該產品已成功運行三年,滿足日活百萬的企業。產品結構很簡單,用世上最簡單的語言php,最普遍的數據庫mysql,服務器可以選擇apache也可以選擇nginx,一切看你自己的喜好。
一、微服務架構圖
整個流程圖:
1、SDK上傳數據到服務器,如果安裝redis做緩存,數據會最先進到redis,然后定時抽取數據到DB服務器。有了redis可以大大提高并行數據處理能力。
2、數據庫收集原始數據,存儲過程將數據按照不同維度統計各個指標數據,同時將數據匯總表。
3、前臺報表展示,實時報表、小時報表和天報表數據展示。最好做到讀寫分離。
二、功能架構

功能架構主要包括功能、角色和權限三部分。功能是企業服務,用戶使用的每一個功能,就是企業的每一個服務。角色是用戶操作的歸類,功能與角色的對應關系及權限。了解系統架構的現狀,從功能架構開始。
三、應用架構
應用架構的內容包括現有架構圖、web應用現狀和接口架構。其中,接口是應用層面的關鍵,它是程序之間交互的部分。
主要包括clientdata、usinglog、event和errorlog等接口。
SDK通過接口定時發送數據到后臺。
應用架構羅列出前后端調用關系。
四、數據設計
兩個數據庫,大約一百張表。數據庫的設計依賴業務數據,對業務數據歸類,導致數據設計畫出E_R圖,數據設計完成,最終數據庫設計就出來了。數據庫只要早起設計的號,是可以做到易伸縮、易拆分的。統計類主要分為統計的維度,還有就是用戶、設備、錯誤信息等。
1、數據處理能力
日活百萬,啟動次數大概兩百萬,事件數和頁面訪問量起碼在三百到五百萬之間,平均每小時數據量五十萬。運行過程中,**客戶數據量集中在早晚高峰。根據客戶的特殊情況,會把一些任務安排在閑暇時間段,比如日任務、周任務、月任務等安排在零晨。
好的硬件配置是數據處理的好幫手,更大的內存更快的硬盤絕對可以讓數據流快速執行。
2、數據清洗和讀寫分離
大量原始數據入庫,這些數據處理之后就是垃圾數據了。當所有報表數據都統計之后并寫入各個維度表之后,需要定時把這些數據清除掉。
前臺報表展示數據跟存儲分析數據庫最好分開。
五、物理架構
微服務的物理架構需要的機器很少,一臺機器也能跑起來。分析統計主要是數據處理能力要求很高,數據庫服務器需要兩臺,web端需要一臺足矣。多年運營結果是并發和數據庫處理能力是統計分析的最大瓶頸。
六、繼續優化的方向
1、數據讀寫分離,數據清洗。
2、并發量。
七、客戶
客戶最關心的數據:
每一個客戶最關心的就是用戶表,用戶新增狀況、用戶活躍情況、用戶留存情況。
不同的客戶對用戶要求不同,需要判斷用戶是否是刷機來的,用戶跟設備號及用戶ID(用戶號碼)之間的映射關系。
事件數據也是很重要的,關系轉化率。
頁面訪問跟事件是同等重要。
錯誤數據可以檢測應用存在的Bug。
不同的客戶,不同的使用場景對指標會有不同需求。
Apache NiFi是什么?NiFi官網給出如下解釋:“一個易用、強大、可靠的數據處理與分發系統”。通俗的來說,即Apache NiFi 是一個易于使用、功能強大而且可靠的數據處理和分發系統,其為數據流設計,它支持高度可配置的指示圖的數據路由、轉換和系統中介邏輯。
為了對NiFi能夠表述的更為清楚,下面通過NiFi的架構來做簡要介紹,如下圖所示。
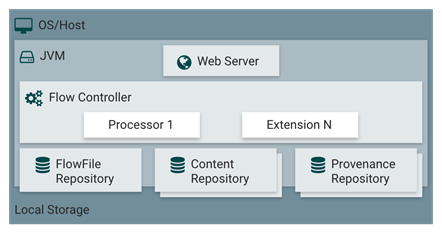
Apache NiFi是什么?NiFi官網給出如下解釋:“一個易用、強大、可靠的數據處理與分發系統”。通俗的來說,即Apache NiFi 是一個易于使用、功能強大而且可靠的數據處理和分發系統,其為數據流設計,它支持高度可配置的指示圖的數據路由、轉換和系統中介邏輯。
為了對NiFi能夠表述的更為清楚,下面通過NiFi的架構來做簡要介紹,如下圖所示。
根據官網對各個組件的說明,做摘要翻譯:
? WebServer:其目的在于提供基于HTTP的命令和控制API。
? Flow Controller:這是操作的核心,以Processor為處理單元,提供了用于運行的擴展線程,并管理擴展接收資源時的調度。
? Extensions:在其他文檔中描述了各種類型的NiFi擴展,Extensions的關鍵在于擴展在JVM中操作和執行。
? FlowFile Repository:FlowFile庫的作用是NiFi跟蹤記錄當前在流中處于活動狀態的給定流文件的狀態,其實現是可插拔的,默認的方法是位于指定磁盤分區上的一個持久的寫前日志。
? Content Repository:Content庫的作用是給定流文件的實際內容字節所在的位置,其實現也是可插拔的。默認的方法是一種相對簡單的機制,即在文件系統中存儲數據塊。
? Provenance Repository:Provenance庫是所有源數據存儲的地方,支持可插拔。默認實現是使用一個或多個物理磁盤卷,在每個位置事件數據都是索引和可搜索的。
2 NiFi Processer介紹
上一節說了那么多,主要通過NiFi的架構圖介紹了NiFi的基本概念,由概念可知Flow Controller是NiFi的核心,那么Flow Controller具體是什么?Flow Controller扮演者文件交流的處理器角色,維持著多個處理器的連接并管理各個Processer,Processer則是實際處理單元。那么,讓我們通過NiFi的UI看下NiFi的Processor包含哪些?
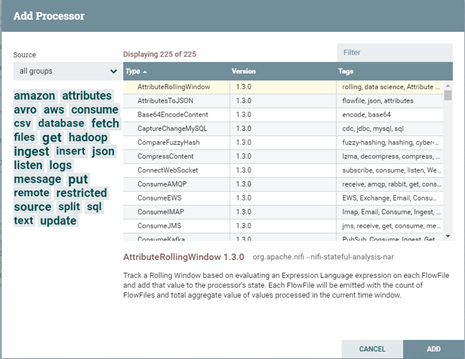
通過上圖可知,Processor包含各種類型的組件,如amazon、attributes、hadoop等,可通過前綴進行輕易辨識,如Get、Fetch開頭代表獲取,如getFile、getFTP、FetchHDFS,execute代表執行,如ExecuteSQL、ExecuteProcess、ExecuteFlumeSink等均可較容易知其簡單用途。
3 NiFi Processer實戰
說了那么多,介紹了NiFi的架構和Processor,那么說好的實戰呢?那么,本文就以筆者的一個實際需求為例,進行Processor的實戰。需求如下:選取一款數據處理調度工具,對服務器腳本實現定制調度執行。其中服務器的腳本涉及到對環境變量、oracle數據庫、Hadoop生態圈組件的調度。當對服務器腳本調度執行完成后返回腳本運行狀態,并提供失敗重運行接口。
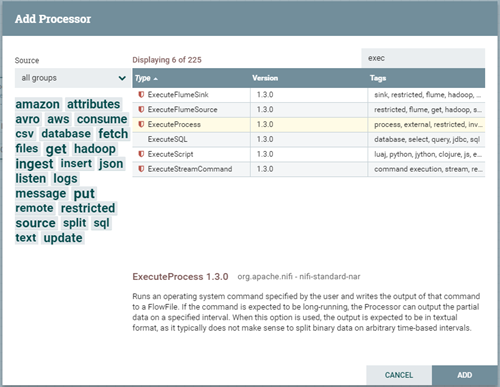
為了實現需求,曾調度過各種調度工具,如Apache Oozie、Azkaban、Pentaho等,最終比較了各種利弊嘗試選用Apache NiFi作為嘗試,通過查閱NiFi Processor API,能更好的支持遠程操作的Processor為ExecuteProcess。下面將對需求進行實戰講解。
3.1 Processor的添加與配置
1. 點擊“Add Processor”,選擇ExecuteProcess后點擊Add按鈕完成添加,如下圖。
2. 右擊ExecuteProcess后選擇Configure Processor,對Properties選項卡進行配置,其中每一個配置選項均提供了相關的說明,如下圖。
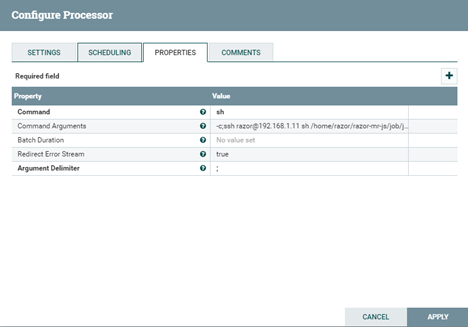
如上圖所示,這里有必要對各選項進行相關說明。
? Command(執行命令): sh。
? Command Arguments(執行命令參數):-c;ssh user@ip sh js/job/job_hourly.sh `date
? Batch Duration(執行間隔時間):不設置。//我們需求是通過定時調度,而并非按間隔時間執行。
? Redirect Error Stream(重定位流):不設置。
? Argument Delimiter(執行命令參數分隔符):; //以;對參數進行分割。
3.2 Processor調度
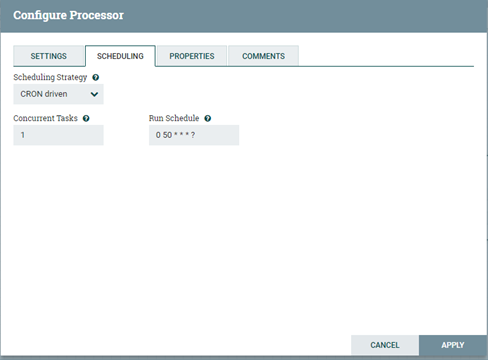
NiFi支持三種調度策略,包括Time Driven(時間驅動)、CRON Driven(CRON驅動)和Event Driven(事件驅動,非可選),根據我們實際需求選擇CRON Driven,個人理解CRON即是Crontab的應用,CRON的各參數含義分別代表:秒、分、時、日、月、周、年,需要配合*、?和L共同執行(*代表字段的值都有效;?代表對于指定的字段不指定值;L代表長整形)。如:“0 0 13 * * ?”代表想要在每天下午1點進行調度執行。因此根據我們的需求進行參數的調度配置。如下圖所示。
3.3 運行狀態監控
NiFi通過Rest API供開發者調度,這里我們用Processor API對運行狀態進行監控(狀態參數獲取、Processor的啟動與停止)。
1. 運行狀態監控參數獲取:
命令如下:curl ‘http://IP/nifi-api/processors/processorsID ‘得到如下結果,可通過json解析器解析并獲取狀態。

2. Processor的啟動與停止:
NiFi的Processor啟動停止通過其Put方法實現,Put最有效的作用是改變其運行狀態,NiFi的Process總共有三種狀態,即Running、Stopped和Disabled。
那么我們將開始和停止兩個命令Rest API的放在腳本中執行即可。
? 啟動命令(使用Rest API的Put方法):
curl -i -X PUT -H ‘Content-Type:application/json’ -d ‘
{
“revision”: {
“clientId”: “586ec1d7-015d-1000-6459-28251212434e”,
“version”:17},
“component”: {
“id”: “39e0dafc-015d-1000-918d-bee89ae2226e”,
“state”: “RUNNING”
}
}’ http://IP/nifi-api/processors/processorsID
? 停止命令(使用Rest API的Put方法):
curl -i -X PUT -H ‘Content-Type:application/json’ -d ‘
{
“revision”: {
“clientId”: “586ec1d7-015d-1000-6459-28251212434e”,
“version”:17},
“component”: {
“id”: “39e0dafc-015d-1000-918d-bee89ae2226e”,
“state”: “STOPPED”
}
}’ http://IP/nifi-api/processors/processorsID
4 小結與后記
本文首先對Apache NiFi進行簡介,后以筆者的實際需求為例,對NiFi核心組件Processor的實戰說明。由于NiFi仍然屬于Apache推出時間不長的一個頂級項目,雖功能十分強大,但可查閱資源仍然有限,本文更多的是一個拋磚的過程,其真正強大的功能還在數據處理上,歡迎感興趣的各位進行互相探討。
]]>由于之前了解一個分布式框架(dubbo)時,其中涉及到zookeeper,因此今天就先來大概的介紹一下zookeeper。zookeeper是一個用來管理大量的主機的分布式協調服務。
(一) 分布式應用程序
分布式應用程序可以通過在它們之間協調以完成特定的任務,快速且有效的方式在多個系統中的網絡在給定時間(同時)運行
分布式應用程序有兩部分,分別是:服務器和客戶端應用程序。如下圖所示:
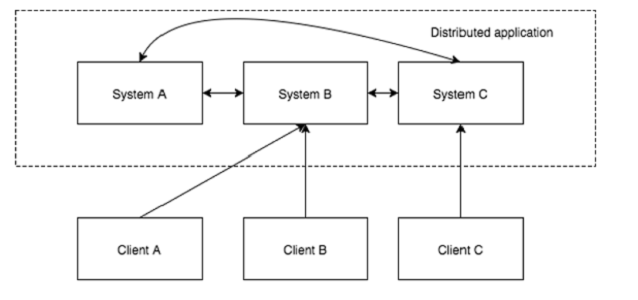
(二) 分布式應用程序的有點
可靠性 可擴展性 透明性
(三) zookeeper提供的服務
命名服務 配置管理 集群管理 節點領導者選舉 鎖定和同步服務 數據注冊表
]]>由于之前了解一個分布式框架(dubbo)時,其中涉及到zookeeper,因此今天就先來大概的介紹一下zookeeper。zookeeper是一個用來管理大量的主機的分布式協調服務。
(一) 分布式應用程序
分布式應用程序可以通過在它們之間協調以完成特定的任務,快速且有效的方式在多個系統中的網絡在給定時間(同時)運行
分布式應用程序有兩部分,分別是:服務器和客戶端應用程序。如下圖所示:
(二) 分布式應用程序的優點
可靠性 可擴展性 透明性
(三) zookeeper提供的服務
命名服務 配置管理 集群管理 節點領導者選舉 鎖定和同步服務 數據注冊表
ZooKeeper基礎
(一) ZooKeeper的體系結構
描繪ZooKeeper 的“客戶端 – 服務器架構,如下圖所示
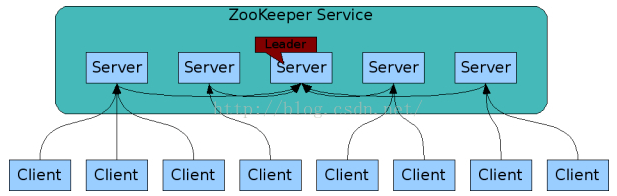
ZooKeeper 架構的一部分組件如下表中所解釋。
1. Client:客戶端,發送消息到服務器。
2. Server:服務器,ZooKeeper集成的一個節點,提供所有的服務給客戶。
3. 合組:ZooKeeper 服務器組。
4. Leader:它執行自動恢復,如果任何連接的節點的故障的服務器節點。
5. Follower:遵循領導指示服務器節點
(二) 分層命名空間
下圖顯示了用于內存中表示 ZooKeeper 文件系統的樹形結構。 ZooKeeper節點被稱為znode。每個znode由一個名稱識別,并通過路徑(/)序列隔開。
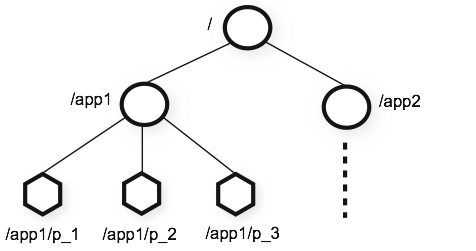
zookeeper名字空間由節點znode構成,其組織方式類似文件系統,其中各個節點相當于目錄和文件,通過路徑作為唯一標識。與文件系統不同的是,每個節點具有與之對應的數據內容,同時也可以具有子節點。在 ZooKeeper 數據模型中每個 znode 維護一個 stat 結構。 一個統計(stat )只是提供了一個 znode 元數據。 它由版本號、動作控制列表(ACL)、時間戳、數據長度組成。
ZooKeeper組件
同一個zookeeper服務下的server有兩種,一種是leader server,另一種是follower server。leader特殊之處在于它有決定權。在zookeeper整個服務下的每臺server將復制各個組件。Replicated Database是包含了所有數據的內存數據庫
Zookeeper之leader
讓我們來分析一下一個領導節點在ZooKeeper集合的選舉。考慮集群中有N多的節點。領導人選舉的過程如下
所有節點創建一個順序,znode具有相同路徑,/app/leader/guid_。
ZooKeeper 的集合將追加的10位序列號的路徑。
對于給定的實例,它在znode創建最小數量的節點成為領導者以及所有其他節點的追隨者。
每一個追隨者節點監控下一個最小號的znode。
Zookeeper安裝配置
(一) 安裝Java(略)
(二) ZooKeeper框架的安裝
1. 下載并tar開解壓(略)
2. 創建配置文件
打開 并編輯conf/zoo.cfg 配置文件,并將以下所有參數設置為開始點。
tickTime = 2000
dataDir = /path/to/zookeeper/data
clientPort = 2181
initLimit = 10
syncLimit = 5
3. 啟動ZooKeeper服務器
$ bin/zkServer.sh start
4. 啟動 CLI
$ bin/zkCli.sh
5. 停止ZooKeeper服務器
$ bin/zkServer.sh stop
Zookeeper CLI
ZooKeeper 命令行界面(CLI)是用來與 ZooKeeper 集成作開發進行交互的。這是在調試和使用不同的選項時的工作有用。
為了執行ZooKeeper的CLI操作, ZooKeeper服務器首先要啟動 (“bin/zkServer.sh start”) , 然后使用 ZooKeeper 客戶端 (“bin/zkCli.sh”). 當客戶端啟動后,可以執行以下操作:(1)創建znodes,(2)獲取數據,(3)監視 znode 變化,(4)設置數據,(5)創建 znode 的子 znode,(6)列出一個 znode 的子 znode,(7)檢查狀態,(8)刪除一個 znode
(一) 創建Znodes
create /path /data
(二) 獲取數據
get /path
(三) 監視
get /path [watch] 1
(四) 設置數據
set /path /data
(五) 創建子znode
create /parent/path/subnode/path /data
(六) 列出子znode
ls /path
(七) 檢查狀態
stat /path
(八) 刪除Znode
rmr /path
Zookeeper 常用API
ZooKeeper有一個Java和C綁定的官方API。ZooKeeper社區提供了對于大多數語言(.NET,Python等)的非官方API。使用ZooKeeper的API,應用程序可以連接,互動,操作數據,協調,以及從ZooKeeper集成斷開。
(一) ZooKeeper的API基礎知識
客戶端應遵循下面給出帶 ZooKeeper 集成一個清晰的交互步驟。
連接到ZooKeeper 。ZooKeeper 集成分配客戶端的會話ID。
定期發送心跳到服務器。否則,ZooKeeper 集成過期的會話ID,那么客戶端需要重新連接。
獲得/設置只要znodes會話ID是活動的。
從 ZooKeeper 集成斷開,當所有的任務都完成后。如果客戶端處于非活動狀態較長時間,那么 ZooKeeper 集成會自動斷開客戶機。
(二) Java綁定
讓我們這一章中理解最重要的ZooKeeper API。ZooKeeper API的中心部分是ZooKeeper 類。它提供了一些選項來連接 ZooKeeper 集成在其構造,有以下幾種方法
? connect ? 連接到 ZooKeeper 的集成
? create ? 創建一個 znode
? exists ? 檢查znode是否存在及其信息
? getData ? 從一個特定的znode獲取數據
? setData ? 設置數據在特定znode
? getChildren ? 得到一個特定 znode 的所有可用子節點
? delete ? 得到一個特定的 znode 及其所有子節點
? close ? 關閉連接
(三) 連接到 ZooKeeper 集合
ZooKeeper類通過它的構造函數提供了連接功能。構造函數如下:
ZooKeeper(String connectionString, int sessionTimeout, Watcher watcher)
(四) 創建一個Znode
ZooKeeper類提供了一個方法來在集合 ZooKeeper 創建一個新的 znode。創建方法如下:
create(String path, byte[] data, List acl, CreateMode createMode)
(五) Exists – 檢查一個Znode的存在
exists 方法來檢查 znode 的存在。如果指定的 znode 存在它返回一個 znode 元數據。exists 方法如下
exists(String path, boolean watcher)
(六) getData 方法
getData方法來獲取連接在指定 znode 及其狀態的數據。getData方法如下
getData(String path, Watcher watcher, Stat stat)
(七) setData 方法
SetData方法來修改附著在指定 znode 的數據。SetData方法如下
setData(String path, byte[] data, int version)
(八) getChildren 方法
getChildren方法來得到一個特定的 znode 所有子節點。getChildren 方法如下
getChildren(String path, Watcher watcher)
(九) 刪除一個Znode
delete 方法來刪除指定 znode。delete方法如下
delete(String path, int version)
]]>Baeyens就推出了基于JBPM4工作流引擎的開源工作流系統Activiti。
Activiti淺析,首發于Cobub。
]]>Baeyens就推出了基于JBPM4工作流引擎的開源工作流系統Activiti。
Activiti框架以及JBPM5框架都是BPM(Bussiness Process Manage)系統(符合BPM規范),都是BPMN2過程建模和執行環境。都是開源項目-遵循ASL協議( Apache的 軟件許可)。 都源自JBoss(Activiti5是jBPM4的衍生,jBPM5則基于Drools Flow)。 都很成熟,從無到有,雙方開始約始于2年半前。 都有對人工任務的生命周期管理。 Activiti5和jBPM5唯一的區別是jBPM5基于WebService – HumanTask標準來描述人工任務和管理生命周期。 如有興趣了解這方面的標準及其優點,可參閱WS – HT規范介紹 。 都使用了不同風格的 Oryx 流程編輯器對BPMN2建模。 jBPM5采用的是 Intalio 維護的開源項目分支。 Activiti5則使用了Signavio維護的分支。
那么activiti作為一種工作流框架,目前廣泛應用于眾多軟件開發公司。那么如果想要使用activiti開源工作流系統實現自己的業務系統,那么其實首先第一步,是要熟悉BPMN2.0的規范,當然這一步也不是必須的。BPMN2.0規范作為一種標準實現的是工作流業務系統當中可能會遇到的一些基本模型的建立。
目前主流的Java開發IDE為eclipse和intellij idea。這兩個開發工具都有支持Activiti的開發,擁有界面式的流程編輯器。通過對業務流程進行繪制,流程編輯器會對業務流程進行解析并生成一個.bpmn文件,其實質上就是一個.xml文件,該文件當中聲明式的說明了各個流程的實現以及業務類型,后續通過Activiti的流程引擎可以對該xml文件進行解析,并執行對應的操作及流程跳轉功能。
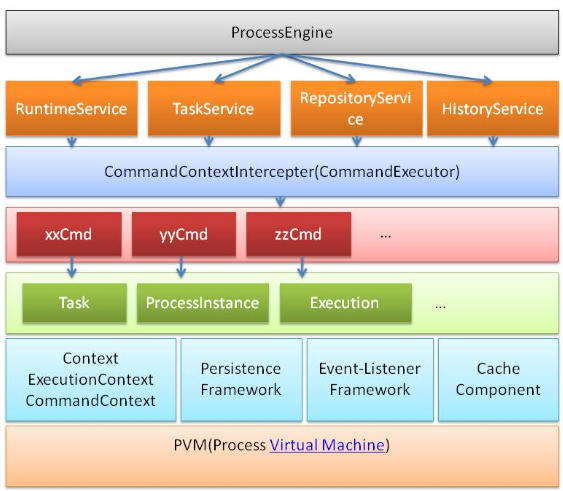
這里給出Activiti的Github社區網址,相關內容可以到上面下載咨詢。那么Activiti工作流系統基于的工作流引擎到底是個什么東西呢?目前Activiti工作流業務系統提供了一套基于java的API接口,流程引擎其實它是一個class類的實例,只是通過這個對象可以獲取到所有的關于工作流業務流程的內容以及操作所有的流程進行。如圖1.1是工作流引擎對象以及其可以派生的對象:
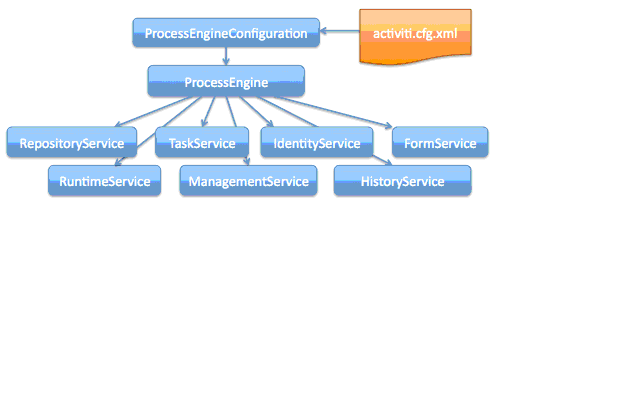
其中,activiti.cfg.xml文件為核心配置文件,該配置文件集成在Spring的IOC容器當中,可以產生ProcessEngineConfiguration對象,這個對象就是流程引擎的配置對象,ProcessEngine對象則為流程引擎對象,該對象是工作流業務系統的核心,所有的業務操作都是由這個對象所派生出來的對象實現。關于對象的操作請參考Activiti5的API文檔。
目前的Activiti5工作流業務系統總共涉及23張表,如圖1.2為表的相關信息。當然這些表并不是都是必須的,有些用不到的功能的表自然而然就不需要了。目前Activiti5的工作流業務系統支持MySql、Oracle和DB2等主流數據庫,默認使用的數據庫為H2。相關數據庫的配置參考相關文檔。

Activiti工作流業務系統對Spring的集成非常好,這對于熟悉Spring框架的開發人員來說是一種比較好的特性。但是Activiti框架當中并不是封裝了業務功能,只是實現了最基本的操作,可以使使用者更好地實現某些功能,但是由于activiti中并沒有對駁回進行有效的封裝,所以如果開發人員想使用駁回功能,那就需要自己通過activiti的API自己手動的封裝一個接口了。
那么對于Activiti工作流框架,我們怎么來使用呢?接下來,我們就來簡單的說一說activiti的使用方式。既然要使用activiti框架,先來看看Activiti的基礎編程框架:
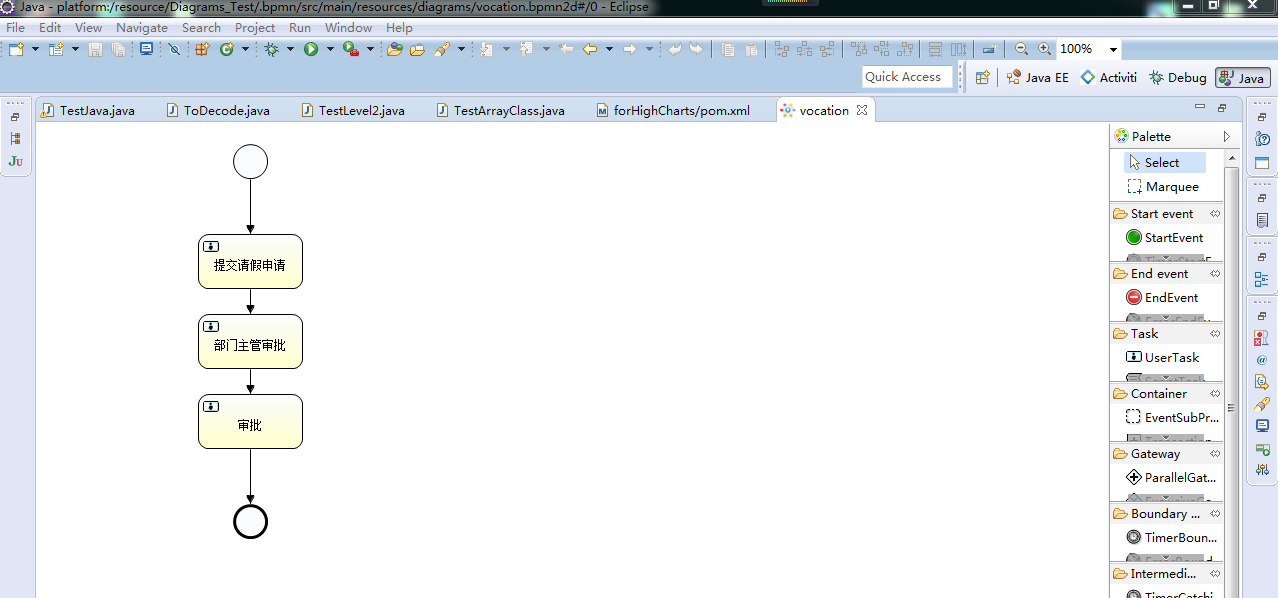
接下來第一步是需要開發工具,前面我們說了,可以使用集成了acitiviti界面式流程編輯器功能的eclipse或者intellij idea。那么這里我們使用eclipse開發工具。如下圖所示:
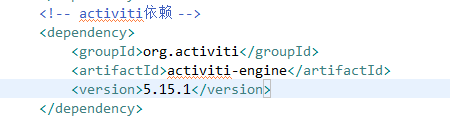
第二步:則需要引入對應的activiti的jar包,可以手動下載下來,也可以使用maven項目管理工具統一管理軟件包。那么這里我們使用maven項目管理工具:
第三步:前面我們說過,activiti工作流業務系統需要23張表,那么表的創建那也是必不可少的,之前我們說過。可以通過activiti的工作流引擎的對象來創建。在這里我們就使用這種方式創建。

完成了上面的三步之后,那么接下來就是簡單的實現一個請假業務流程。第一步,畫流程圖,設置流程開始節點start和結束節點end,設置任務userTask。如下圖所示:
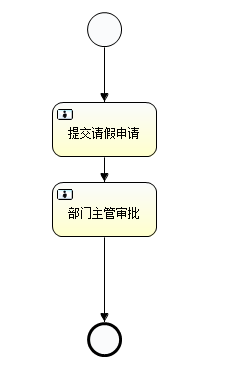
需要注意的是,該流程圖中的每一個userTask都需要設置下一個處理人assignee,可以使用流程變量動態設置處理人,也可以直接固定處理人,這里我們先固定處理人。如下圖所示:
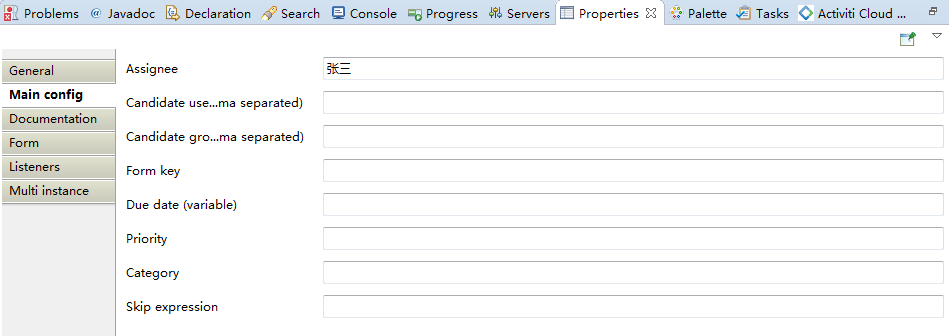
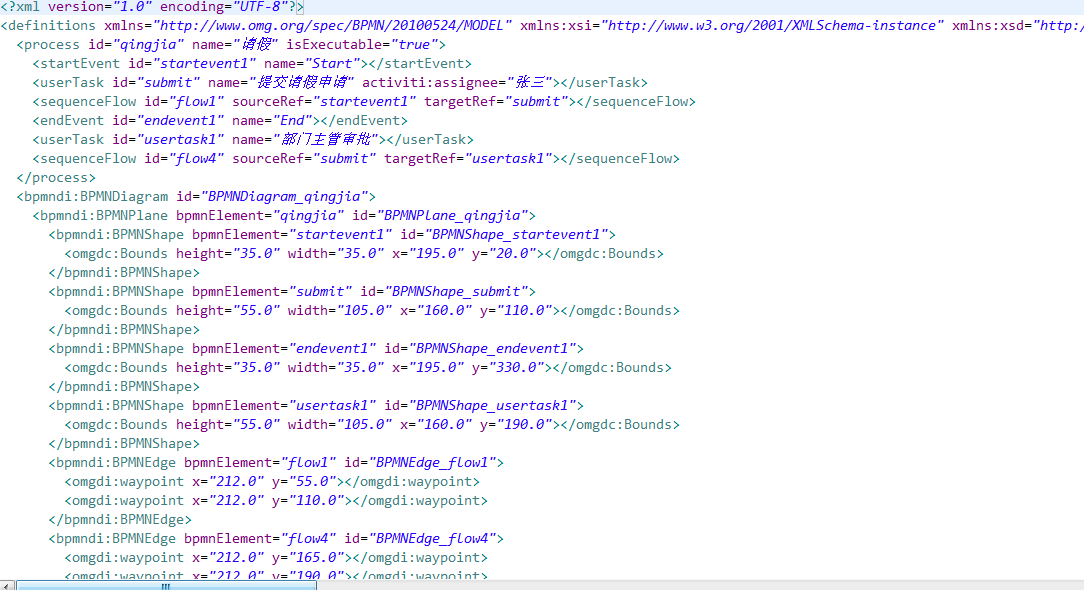
完成了請假業務流程之后,我們來看看這個bpmn文件到底是個什么類型的文件,我們使用txt文本編輯器打開,發現類似于一個xml文件,只是后綴為.bpmn而已。如下圖所示:
接下來就是開始真正的代碼編寫了。前面我們說過activiti工作流框架與Spring幾乎完美的融合,但是這里我們只是涉及到activiti淺析,所以本文只是使用原生的api接口實現簡單的請假流程。
首先使用工作流引擎配置對象加載activiti.cfg.xml文件,前面說過activiti.cfg.xml為工作流的配置文件,這里貼出activiti的內容,使用的數據庫為mysql數據庫。
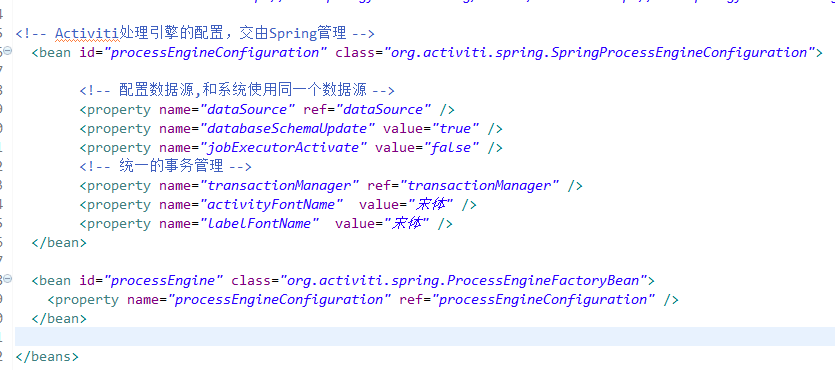
接下來可以使用流程引擎對象ProcessEngineConfiguration加載配置文件,通過配置對象獲取ProcessEngine對象,但是我們不采用配置文件的形式創建這個對象,那么接下來所有的內容都可以使用這個對象派生出來的內容完成所有的功能。其實剛才創建表的那段代碼就可以完成這個功能。
使用ProcessEngine對象加載請假流程配置文件,創建流程定義模板,也即是部署流程。接下來通過流程定義模板創建一個流程實例對象,填寫請假單,保存請假單,即創建一個請假流程。

這段代碼創建了請假流程的定義。

其中,engine為ProcessEngine的實例對象,processDefinitionId為流程定義的Id,該值在創建流程定義的時候就會生成,run.startProcessIntanceById為通過流程定義Id創建一個流程實例對象,這個流程實例對象就對應的是一次請假流程。
在通過創建的請假流程中,再提交請假流程到上級部門(例如:部門經理等),部門經理通過后,才能說明該請假流程完成,10002為任務的唯一標識。對應的流程圖中的每一個任務userTask對應一個taskId。
在本文中,請假流程的例子并沒有涉及到數據庫的操作,也就是說所有的數據庫的內容都是由activiti框架為我們完成,我們只需要實現對應的業務流程即可。這極大的簡化了工作流的相關內容,但是如果想要用好activiti工作流框架,那么就必須對這一套api文檔進行詳盡細致的了解及學習。如果想了解更多關于activiti對數據庫操作的內容。請參閱相關資料。
Activiti淺析,首發于Cobub。
]]> RPC(Remote Procedure Call Protocol)——遠程過程調用協議,它是一種通過網絡從遠程計算機程序上請求服務,而不需要了解底層網絡技術的協議。
RPC采用客戶機/服務器模式。請求程序就是一個客戶機,而服務提供程序就是一個服務器。首先,客戶機調用進程發送一個有進程參數的調用信息到服務進程,然后等待應答信息。在服務器端,進程保持睡眠狀態直到調用信息到達為止。當一個調用信息到達,服務器獲得進程參數,計算結果,發送答復信息,然后等待下一個調用信息,最后,客戶端調用進程接收答復信息,獲得進程結果,然后調用執行繼續進行。
以上是百度百科對RPC的解釋。
一個通俗的描述是:客戶端在不知道調用細節的情況下,調用存在于遠程計算機上的某個對象,就像調用本地應用程序中的對象一樣。
RPC(Remote Procedure Call Protocol)——遠程過程調用協議,它是一種通過網絡從遠程計算機程序上請求服務,而不需要了解底層網絡技術的協議。
RPC采用客戶機/服務器模式。請求程序就是一個客戶機,而服務提供程序就是一個服務器。首先,客戶機調用進程發送一個有進程參數的調用信息到服務進程,然后等待應答信息。在服務器端,進程保持睡眠狀態直到調用信息到達為止。當一個調用信息到達,服務器獲得進程參數,計算結果,發送答復信息,然后等待下一個調用信息,最后,客戶端調用進程接收答復信息,獲得進程結果,然后調用執行繼續進行。
以上是百度百科對RPC的解釋。
一個通俗的描述是:客戶端在不知道調用細節的情況下,調用存在于遠程計算機上的某個對象,就像調用本地應用程序中的對象一樣。
RPC產生的背景
早期單機時代,一臺電腦上運行多個進程,大家各干各的,老死不相往來。假如A進程需要一個畫圖的功能,B進程也需要一個畫圖的功能,程序員就必須為兩個進程都寫一個畫圖的功能。這不是整人么?于是就出現了IPC(Inter-process communication,單機中運行的進程之間的相互通信)。OK,現在A既然有了畫圖的功能,B就調用A進程上的畫圖功能好了。
到了網絡時代,大家的電腦都連起來了。以前程序只能調用自己電腦上的進程,能不能調用其他機器上的進程呢?于是就程序員就把IPC擴展到網絡上,這就有了RPC。
這個時候畫圖功能就可以作為一個獨立的服務提供給客戶機使用。
RPC框架特性
RPC是協議
既然是協議就只是一套規范,那么就需要有人遵循這套規范來進行實現。目前典型的RPC實現包括:Dubbo、Thrift、GRPC、Hetty等。
網絡協議和網絡IO透明
既然RPC的客戶端認為自己是在調用本地對象。那么傳輸層使用的是TCP/UDP還是HTTP協議,者是一些其他的網絡協議它就不需要關心了。既然網絡協議對其透明,那么調用過程中,使用的是哪一種網絡IO模型調用者也不需要關心。
信息格式對其透明
在本地應用程序中,對象調用需要傳遞一些參數,會返回一個調用結果。對象內部是如何使用這些參數,并計算出處理結果的,調用方是不需要關心的。那么對于RPC來說,這些參數會以某種信息格式傳遞給網絡上的另外一臺計算機,這個信息格式是怎樣構成的,調用方是不需要關心的。
有跨語言能力
調用方實際上也不清楚遠程服務器的應用程序是使用什么語言運行的。那么對于調用方來說,無論服務器方使用的是什么語言,本次調用都應該成功,并且返回值也應該按照調用方程序語言所能理解的形式進行描述。
RPC框架的工作原理

1. 調用客戶端句柄;執行傳送參數
2. 調用本地系統內核發送網絡消息
3. 消息傳送到遠程主機
4. 服務器句柄得到消息并取得參數
5. 執行遠程過程
6. 執行的過程將結果返回服務器句柄
7. 服務器句柄返回結果,調用遠程系統內核
8. 消息傳回本地主機
9. 客戶句柄由內核接收消息
10. 客戶接收句柄返回的數據
自己實現RPC框架要做的工作

代碼實現要做的工作
1、 設計對外的接口
public interface IService extends Remote {
public String queryName(String no) throws RemoteException;
}
2、 服務端的服務實現
public class ServiceImpl extends UnicastRemoteObject implements IService {
private static final long serialVersionUID = 682805210518738166L;
protected ServiceImpl() throws RemoteException {
super();
}
@Override
public String queryName(String no) throws RemoteException {
// 方法的具體實現
return String.valueOf(System.currentTimeMillis());
}
}
3、 RMI服務端實現
public class Server {
public static void main(String[] args) {
Registry registry = null;
try {
// 創建一個服務注冊管理器
registry = LocateRegistry.createRegistry(8088);
} catch (RemoteException e) {
}
try {
// 創建一個服務
ServiceImpl server = new ServiceImpl();
// 將服務綁定命名
registry.rebind("vince", server);
} catch (RemoteException e) {
}
}
}
4、 客戶端實現
public class Client {
public static void main(String[] args) {
Registry registry = null;
try {
// 獲取服務注冊管理器
registry = LocateRegistry.getRegistry("127.0.0.1",8088);
} catch (RemoteException e) {
}
try {
// 根據命名獲取服務
IService server = (IService) registry.lookup("vince");
// 調用遠程方法 ,獲取結果。
String result = server.queryName("ha ha ha ha");
} catch (Exception e) {
}
}
}
]]>首先來看一下jQuery的總體結構代碼1-1:
(function(window,undefined){
//構造JQuery對象
var jQuery = (function(){
var jQuery = function(selector,context){
return new jQuery.fn.int(selector,context,rootjQuery);
}
return jQuery;
})();
//工具方法Utilities
//回調函數列表Callbacks Object
//異步隊列 Deferred Object
//瀏覽器功能測試 Support
//數據緩存 Data
//隊列 Queue
//屬性操作 Attribute
//事件系統 Events
//選擇器 Sizzle
//DOM 遍歷 Traversing
//DOM 操作 Manipulation
//樣式操作 CSS(計算樣式,內聯樣式)
//異步請求 Ajax
//動畫 Effects
//坐標 Offset ,尺寸 Dimensions
window.jQuery = window.$ = jQuery;
})(window);
代碼1-1
從上面的代碼中我們可以看到jquery的所有代碼都是寫在了一個立即執行的匿名函數中,這種函數叫“自調用匿名函數”。當瀏覽器加載了jQuery的js文件后,自調用匿名函數就會立即執行,給jQuery初始化各個模塊。
首先講一下用自調用匿名函數的優點,創建自調用匿名函數就相當于創建了一個特殊的函數作用域,該函數中的代碼不會和已有的同名函數、方法和變量沖突。所以jQuery的代碼不會受到其他代碼的干擾,而且也不會污染全局變量,從而影響其他代碼。自調用匿名函數還有兩種寫法,如下:
//寫法1
(function(){
//......
}());
//寫法2
!function(){
//......
}();
代碼1-2
從代碼1-1中我們可以看到在自調用匿名函數的最后將jQuery添加到了window對象上,從而使得變量jQuery成為公開的全局變量,其他部分將是私有的。給自調用匿名函數設置參數window,并傳入window對象,可以將window對象變為局部變量(把函數參數作為局部變量使用),這樣當在jQuery代碼塊中訪問window對象時,不需要退回頂層作用域,可以快速的訪問window對象。
給自調用匿名函數設置undefined,因為特殊值undefined是window對象的一個屬性,例如:
alert("undefined" in window); //true
執行以上代碼將會彈出true。通過這種方式可以為確保參數undefined的值是undefined,因為undefined有可能會被重寫為新的值。可以用下面的代碼來嘗試修改undefined的值:
undefined = "now is's defined";
alert( undefined );
當然,在高版本的瀏覽器中這種寫該方法已經不支持了,比如IE9.0以上、Chrome 17.0.963.56以上和Firefox 4.0版本都是不能改變的。
通常在JavaScript中,如果語句分別放在不同的行,則分號(;)是可選的可寫可不寫,但是對于自調用匿名函數來說,在之前或之后省略分號都有可能會引起語法錯誤。如下代碼執行就會拋出異常:
例1
var n = 1
(function(){})()
//TypeError: number is not function
在上面的代碼中,如果自調用匿名函數的前一行末尾沒有加分號,則自調用匿名函數的第一對括號會被當作是函數調用。
例2
(function(){})()
(function(){})()
//TypeError: undefined is not function
在上面的代碼中,如果未在第一個自調用匿名函數的末尾加分號,則下一行自調用匿名函數的第一對括號會被當作是函數的調用。所以,在使用自調用匿名函數時,最好不要省略自調用匿名函數的之前和之后的分號。
jQuery對象是一個類數組對象,含有連續的整型屬性、length屬性和大量的JQuery方法。jQuery對象由構造函數jQuery()創建,$()則是jQuery() 的縮寫。如果調用構造函數jQuery() 時傳入的參數不同,創建jQuery對象的邏輯也會隨之不同。構造函數jQuery()有7種用法,如下圖:

這次主要是先將jQuery的總體結構講一下,其他的等下次分享。推薦大家看《深入解析jQuery架構設計與實現原理》一書,關于jquery的技術點講的特別細。